How Mozilla Fixed 500 Security Bugs with Claude Mythos
Mozilla's Brian Grinstead reveals the custom AI agent workflows they built to find and patch hundreds of security bugs in Firefox, a process you can adapt for your own projects.
Claire Vo

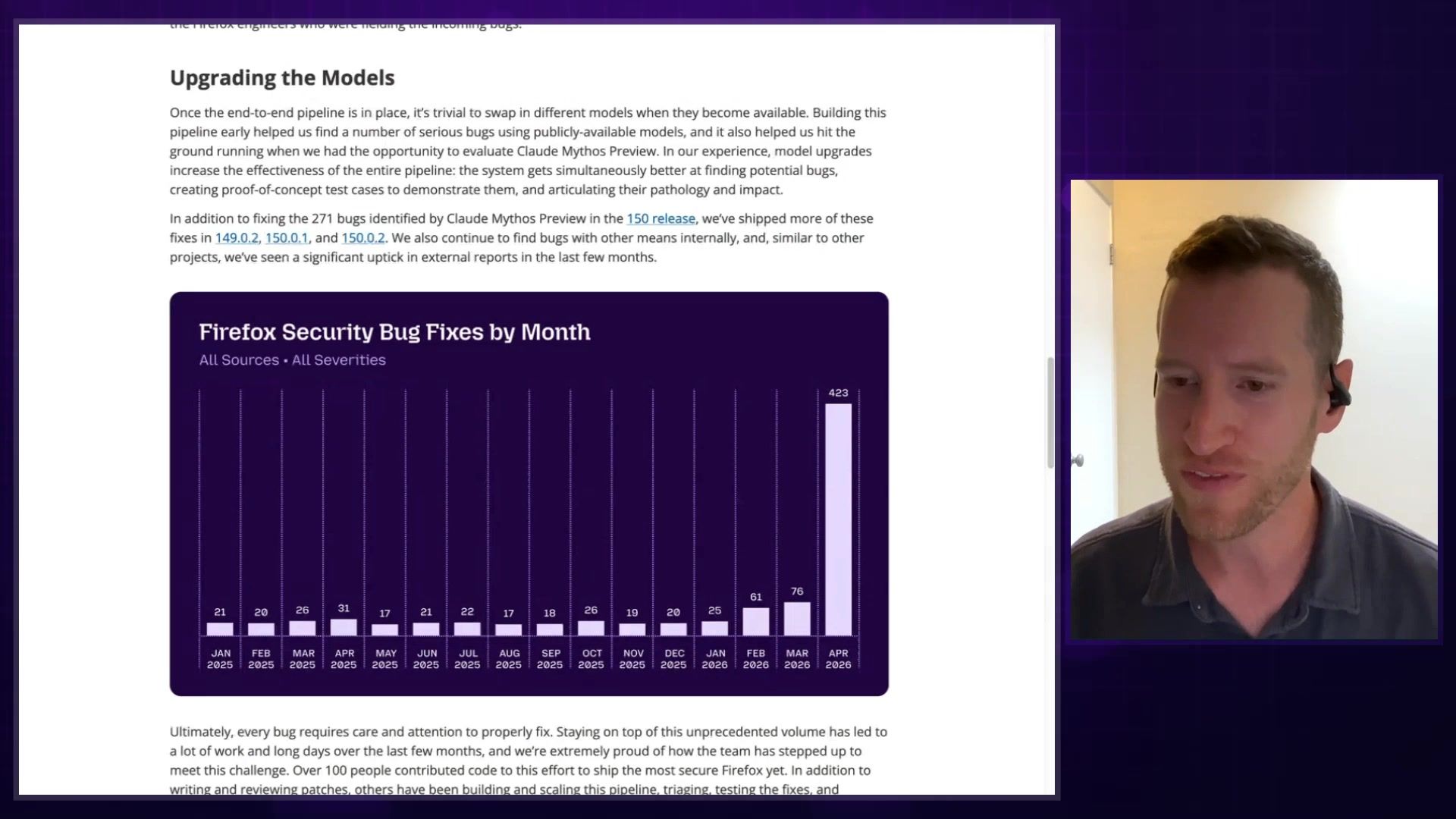
In my journey exploring how people are building with AI, I occasionally come across a story that fundamentally shifts my perspective on what's possible right now. Today’s episode is one of those stories. I was so excited to sit down with Brian Grinstead, a Distinguished Engineer at Mozilla who has been working on Firefox for over a decade. You may have seen a chart that went viral on X, showing an unbelievable spike in security bug fixes for Firefox—nearly 500 in a single month. The headline was often attributed to a mysterious, not-yet-released Anthropic model supposedly called "Mythos."
But as Brian explains, the model is only part of the story. The real unlock came from the custom, agentic workflows the Mozilla team built around the model. They created a system to relentlessly hunt for, verify, and even patch security vulnerabilities, some of which had been hiding in the massive Firefox codebase for over 15 years. This isn't just a story about a powerful new model; it's a story about clever engineering and the incredible leverage you get when you give an AI agent a clear goal and the right tools for the job.
In our conversation, Brian demystified the entire process, breaking it down into three core workflows that any engineering team can learn from and adapt. We walk through how they built a custom agentic harness for bug detection, a clever LLM-based system for prioritizing work, and a patching agent that proposes and verifies fixes. This is one of the most impactful stories in AI engineering right now, and it’s full of practical lessons on moving beyond simple chatbots to build truly powerful AI systems.
Workflow 1: Building a Custom Agentic Harness for Relentless Bug Hunting
Before this initiative, the Mozilla team was dealing with what Brian called "unwanted AI bug reports." Security researchers would paste C++ code into a chatbot, get a plausible-sounding but often incorrect vulnerability report, and file it. This created an asymmetric cost for the maintainers, who had to spend significant time debunking these false positives. The game changed when they decided to build their own system that could not only find bugs but also prove they were real.
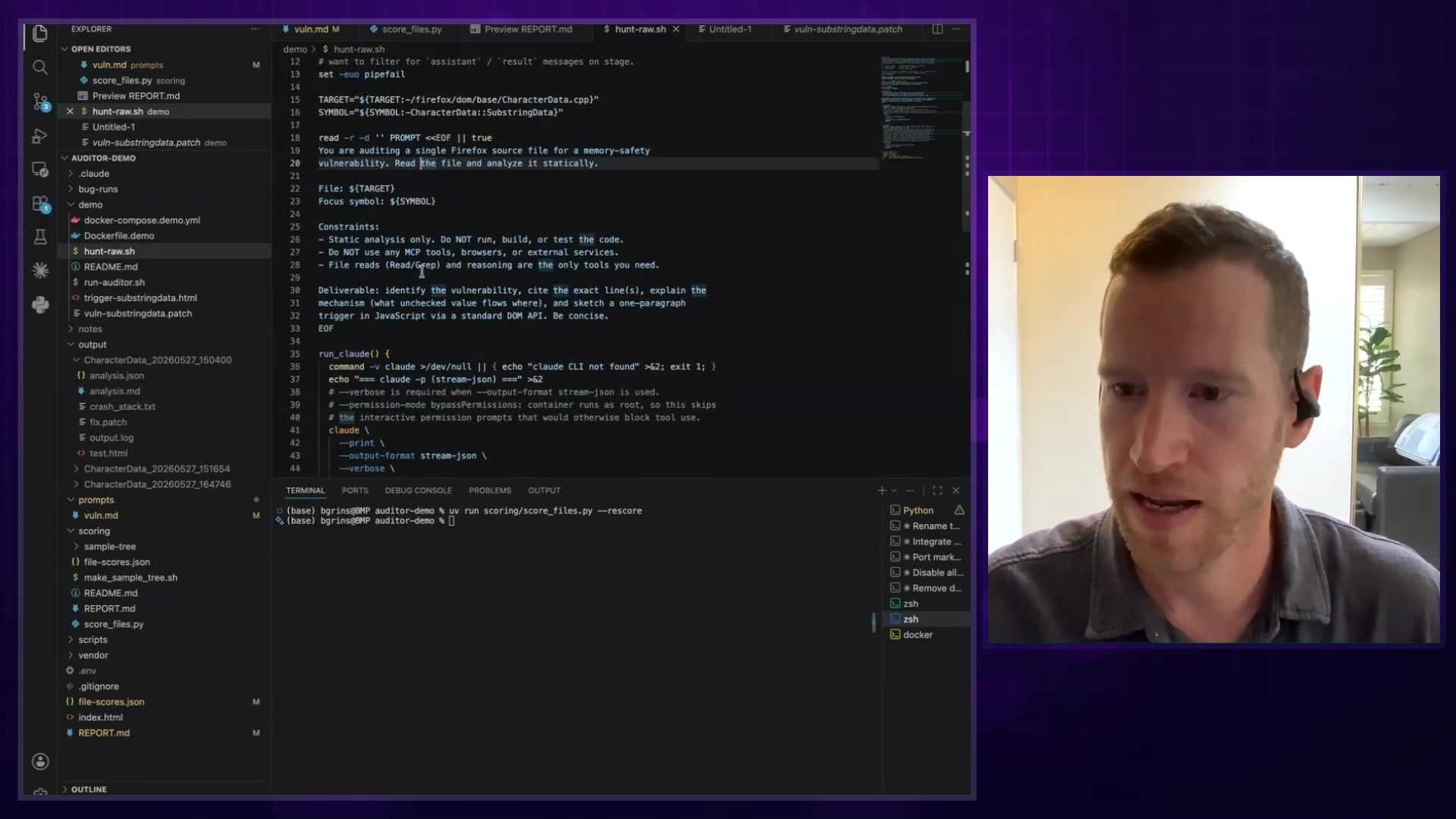
The core of their solution is a custom "harness." A harness is essentially a system that gives an LLM tools to achieve a goal. Instead of a "brain in a jar" that can only chat, the agent gets access to a terminal, can run scripts, build the software, and use specialized tools to verify its findings. It’s the key to turning a model’s reasoning ability into concrete, verifiable action.
The Bug-Hunting Process
Here’s a step-by-step breakdown of how their main bug-hunting agent works:
- Target Selection: The process starts with a specific source code file, identified as a high-priority target by a separate scoring workflow (which we’ll cover next).
- The Agent Loop: The system kicks off what Brian calls the "main agent loop," which is orchestrated using the Claude Agent SDK. This agent is given a checkout of the Firefox codebase and a specific mission.
- The Creative Lie: This is where it gets clever. They prompt the agent with a little lie: "We know there's a security bug in this file. You have to go find it." This focuses the agent and encourages it to be relentless.
- Hypothesize and Test: The agent begins to reason about the code, trying to figure out how a malicious webpage could exploit it. It forms hypotheses and generates HTML test cases to try to trigger a crash.
- Tool Use: The harness gives the agent access to tools, including a
browser_evaluatorthat runs the generated HTML test case inside a special build of Firefox equipped with an address sanitizer, which can detect memory safety issues. - Relentless Iteration: The agent loops, receiving feedback from the tools. If a test case fails to produce a crash, it analyzes why and tries again. Brian shared an example where the agent tried 14 times before it finally succeeded in finding a bug in the
<legend>HTML element. - Verified Output: When the agent successfully triggers a crash, the system doesn't just get a report. It gets the exact, reproducible HTML test case that proves the vulnerability exists. As Brian put it, having that reproducible test case “is exactly the thing… that makes this approach different from previous attempts.”
This workflow is so powerful because it combines the reasoning and code-generation capabilities of a model like Claude with the rigorous, automated verification of Mozilla's existing developer tooling. It finds bugs that are incredibly hard for humans to discover because it never gets tired, bored, or gives up.

Workflow 2: Using an LLM Judge to Prioritize Where to Look
With tens of millions of lines of code, you can't just tell an agent, "Go find all the bugs in Firefox." It's too vast, and the process is too expensive. You need to point it in the right direction. This led the team to build a second, equally clever workflow: an LLM-powered judge to score and prioritize files for the main harness.
This approach solves a critical problem of scale. By focusing the agent's attention on the most likely areas, they make the entire operation more efficient and effective. This is a pattern I think is massively useful for anyone working on a large codebase, whether you’re tackling security, performance, or tech debt.
How the LLM Judge Works
The process is surprisingly straightforward:
- Craft a Prompt: They created a prompt that turns a large language model into a security expert. The prompt provides context on different file types in the Firefox codebase (like C++ files,
Web IDLfiles, etc.) and details from their existing security bug classification program. - Request Two Scores: The prompt asks the LLM to provide two scores for each file on a given scale:
- Score 1: Likelihood: How likely is it that this file contains a memory safety issue?
- Score 2: Accessibility: How easily can this code be accessed from a malicious webpage?
- Generate a Ranked List: They run this scoring process across the codebase, which generates a prioritized list of files. A file like
document.cppgets a very high score because it's huge and directly accessible by web content. - Feed the Harness: This ranked list becomes the input for the main bug-hunting harness, ensuring that expensive compute cycles are spent on the highest-impact targets first.
Here’s the essence of the prompt Brian described:
You're a security expert. Here's the different kinds of files we're looking at: C++ files, IPDL files, Web IDL files. Here is some detail about each... Now, give me two scores. One score is how likely do you think there's a memory safety issue? And another is how easy could you access this from a webpage?
I just love how simple and effective this is. I hear all the time from teams asking, "How do I prioritize tech debt in my monorepo?" This is how! You can adapt this LLM judge pattern to score files based on performance bottlenecks, outdated code patterns, or even poor user experience in UI components.
Workflow 3: From Detection to Patching with a Verification Loop
Finding a bug is great, but it's only half the battle. The final piece of Mozilla's system is a workflow that helps verify and fix the vulnerabilities the main harness discovers. This part of the process introduces a critical guardrail and then moves toward a complete, automated solution.
This workflow demonstrates the importance of building checks and balances into agentic systems. As Brian noted, an agent laser-focused on a goal can do "wonky things," like introducing a new vulnerability just so it can exploit it and claim success. A verifier agent prevents this, ensuring the results are trustworthy.
The Verification and Patching Pipeline
- The Verifier Sub-Agent: After the main agent finds a vulnerability, its output is passed to a verifier sub-agent. This second agent acts as a reviewer, checking to see if the proposed exploit is legitimate. It looks for cheats, like the agent changing the code to introduce the bug or using a developer-only preference that a real user would never have set. This step is crucial for eliminating the false positives that plagued earlier, manual attempts.
- The Patching Agent: Once a bug is fully verified, a separate patching agent is spun up. Its goal is to generate a plausible code patch that resolves the security issue.
- Automated Patch Verification: The harness is already in a loop where it can perform builds. It applies the proposed patch, rebuilds Firefox, and then runs the exact same HTML test case that originally triggered the crash. If the crash no longer occurs, the patch is considered successful.
- The Human Expert in the Loop: The verified patch and the full report are then passed into the standard bug pipeline for a human engineer to review. This is where expert oversight is still essential. For example, Brian showed a bug where the agent produced a correct, but very localized, point fix. The human engineer looked at it and realized the same pattern needed to be fixed in three other places, leading to a more robust, architectural solution.
This highlights the perfect symbiosis of AI and human expertise. The agent does the tedious, relentless work of finding, proving, and proposing a fix for a single instance. The human provides the architectural oversight and context that agents currently lack, turning a point fix into a systemic improvement.
The Future of Building Software
What the Mozilla team has built is a powerful template for the future of software development. The three workflows—Prioritize, Hunt, and Patch—are interconnected parts of a system that augments human engineers, freeing them from tedious work and allowing them to focus on higher-level problems. As I've said before, this is the revenge of the DevX team: organizations that have already invested in strong developer tooling and automation are poised to get a massive force multiplier from these new AI capabilities.
While the story started with a mysterious model called "Mythos," the real lesson is that the model is just one component. The true leverage comes from the thoughtful construction of agentic harnesses around it. This is about giving agents clear, verifiable goals and the tools to achieve them.
I want to encourage everyone to think about how you can apply these patterns. You don't need to be chasing down memory-safety bugs in a web browser. You can build an LLM judge to prioritize areas for performance optimization. You can create an agentic loop that tests your UI components against a set of design principles. The patterns Brian shared are versatile, powerful, and, as he showed us, not nearly as complicated to start building as you might think. For more details, you can read the official post about this work on Substack. A huge thank you to Brian Grinstead and the whole Mozilla team for sharing their work so openly.


