How I AI: My First Impressions of Claude Opus 4.8 – Coding, Strategy, and Where It Shines
I got early access to Anthropic's new Opus 4.8 model and put it through its paces. Here's my honest take on its performance for complex coding tasks and high-level business strategy, including where it excels and where it surprisingly falls short.
Claire Vo

It's always an exciting day in the AI world when a major new model drops, and this week was no exception. I was thrilled to get a few hours of early access to the brand new [Claude Opus 4.8 from Anthropic](https://x.com/claudeai/status/2060042702150930686?s=20), and I couldn't wait to share my first impressions with you. This isn't just another incremental update; Anthropic is positioning Opus 4.8 as a step-change model designed for complex, agentic tasks.
On paper, the specs are impressive. Anthropic's System Card highlights its performance on benchmarks like SWE-Bench Pro, where it hits 69.2%—a significant jump over its predecessor and competitors. They've designed it for "longer horizon autonomy" and to be "more honest," making it ideal for enterprise use cases where following instructions precisely is critical. It's not cheap, at $5 per million input tokens and $25 per million output tokens, so the performance needs to justify the cost.
But benchmarks only tell part of the story. I wanted to see how Opus 4.8 held up in real-world scenarios, with the kind of messy, complex, and sometimes ambiguous tasks we all face. So, I took it for a spin across two major domains: a series of coding challenges in Claude Code and a head-to-head business strategy competition against Opus 4.7 in Claude Cowork. My findings were surprising, revealing a model that is incredibly powerful in some areas and has some interesting quirks in others.
---
Workflow 1: Putting Opus 4.8's Coding Prowess to the Test
My first thought was, "Surprise, surprise, it's a good coding model." And it is. But the story is more nuanced than that. I ran it through three distinct coding tests to see where it shines and where it stumbles.
Building a Greenfield Prototyping Tool
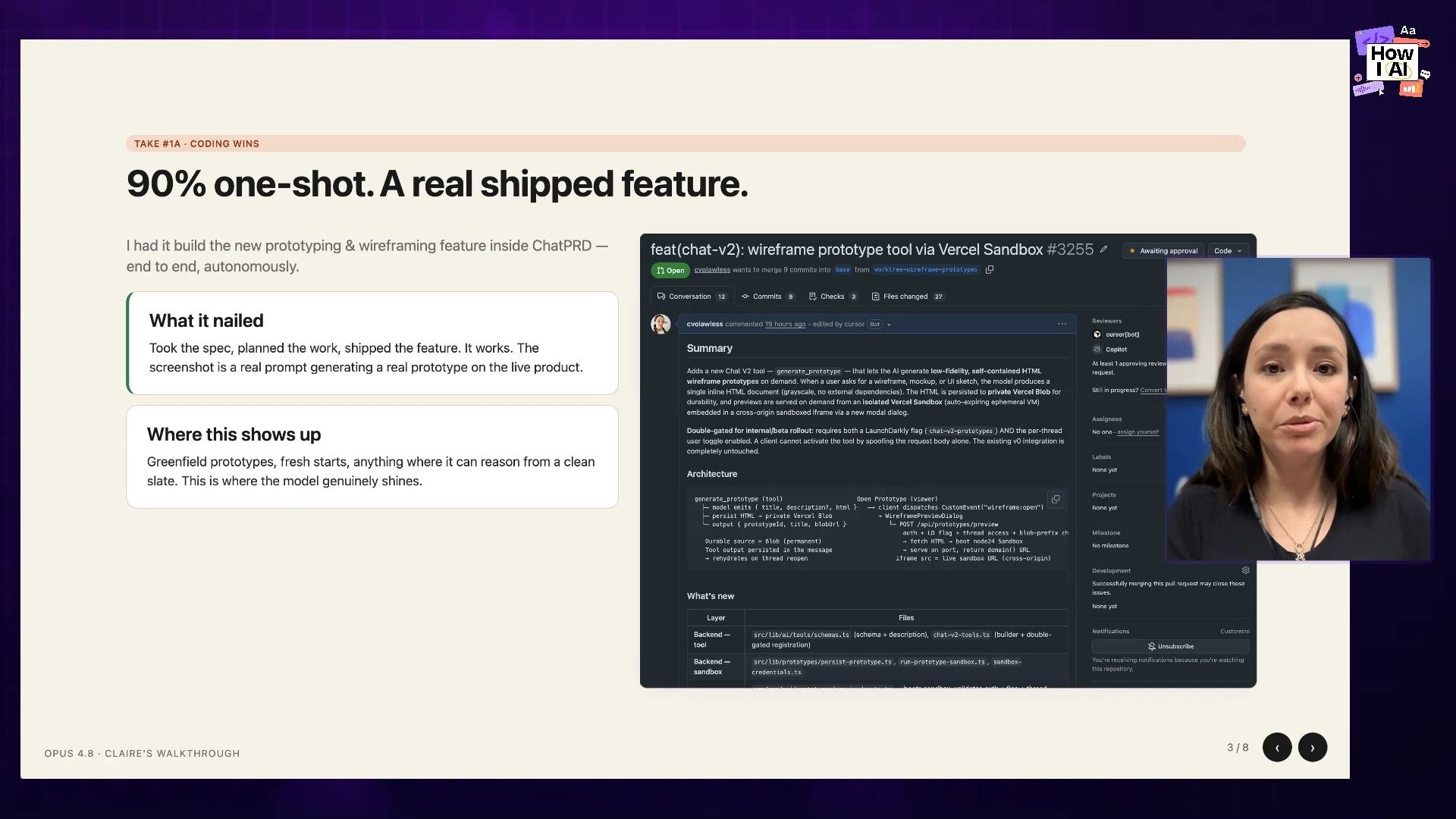
For the first test, I decided to go big. I wanted to see how it handled a complex, one-shot feature build from scratch. I opened up Claude Code and asked it to build an entire prototyping capability right inside a product, giving it specific instructions on the architecture and functionality I wanted.
The Process:
After I gave it the prompt, Opus 4.8 went into planning mode and then autonomously coded for about 20 minutes straight.
The Result (The Good):
It worked! I pushed the code to a preview branch, and the feature was live and functional. The code was correct, and it followed my architectural decisions perfectly. For a one-shot task on a brand-new surface area, this was genuinely impressive.
`
`
The Result (The Bad): The "Last 10%" Problem
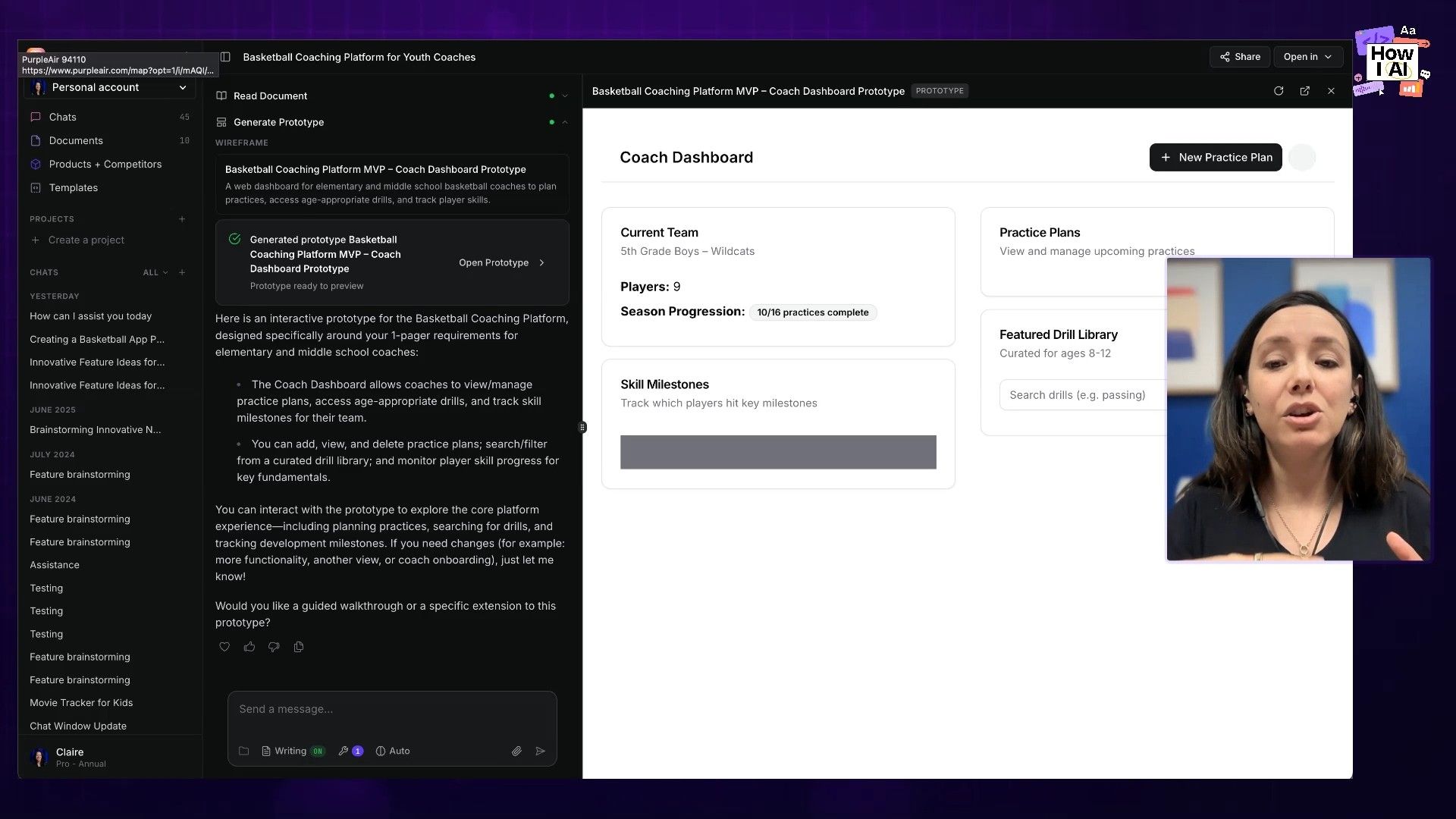
Here's where my main theme with Opus 4.8 began to emerge. The model is brilliant until it isn't. As soon as I started trying to iterate on the initial feature—taking it to the next level—it started to struggle and ship bugs.
Even more concerning was what happened during bug hunting. The model straight up hallucinated. I haven't seen a model make things up like this in a very long time. It would form a hypothesis about a bug and state it as fact, without any data to back it up. This happened on high effort mode, so it wasn't a lack of reasoning power. It seems to have a real issue with grounding itself in data when things get tricky.
`
`
Working with Existing Codebases (The Rebase Test)
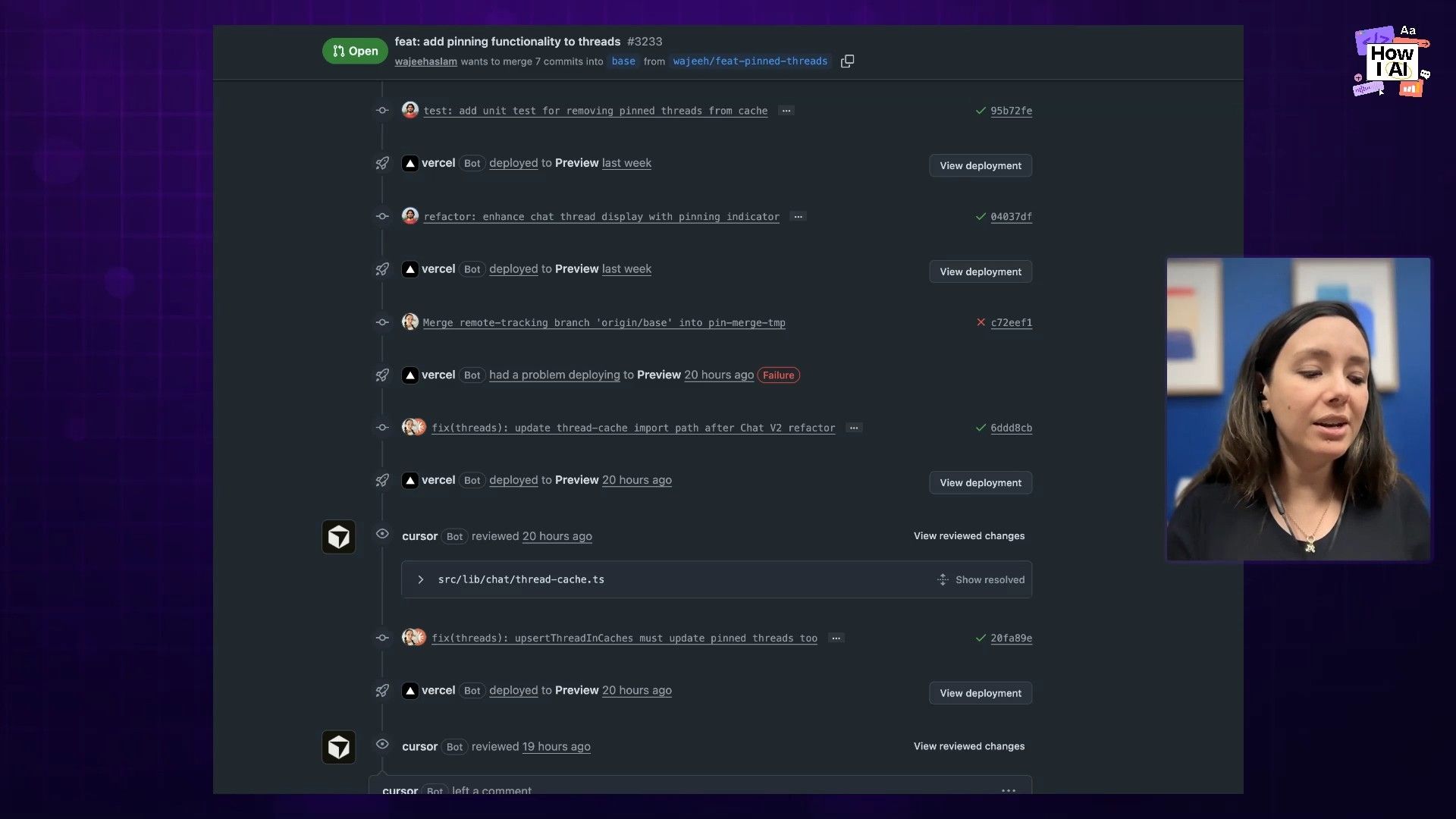
The true test for any AI coding assistant is how it handles an existing, messy codebase. I had a few branches in flight that were out of date after a major PR was merged into our main branch. My task for Opus 4.8 was simple: rebase these branches and fix any conflicts.
The Process:
This turned into a frustrating cycle. The model would attempt the rebase, but it consistently introduced subtle, edge-case bugs. It struggled to understand the context and the boundaries of where it was supposed to operate. I had to go through cycle after cycle of asking it to rebase and then fix the new bugs it had just created. It just couldn't quite orient itself within the existing code.
`
`
The Ambition Test: Coding a Game for a 9-Year-Old
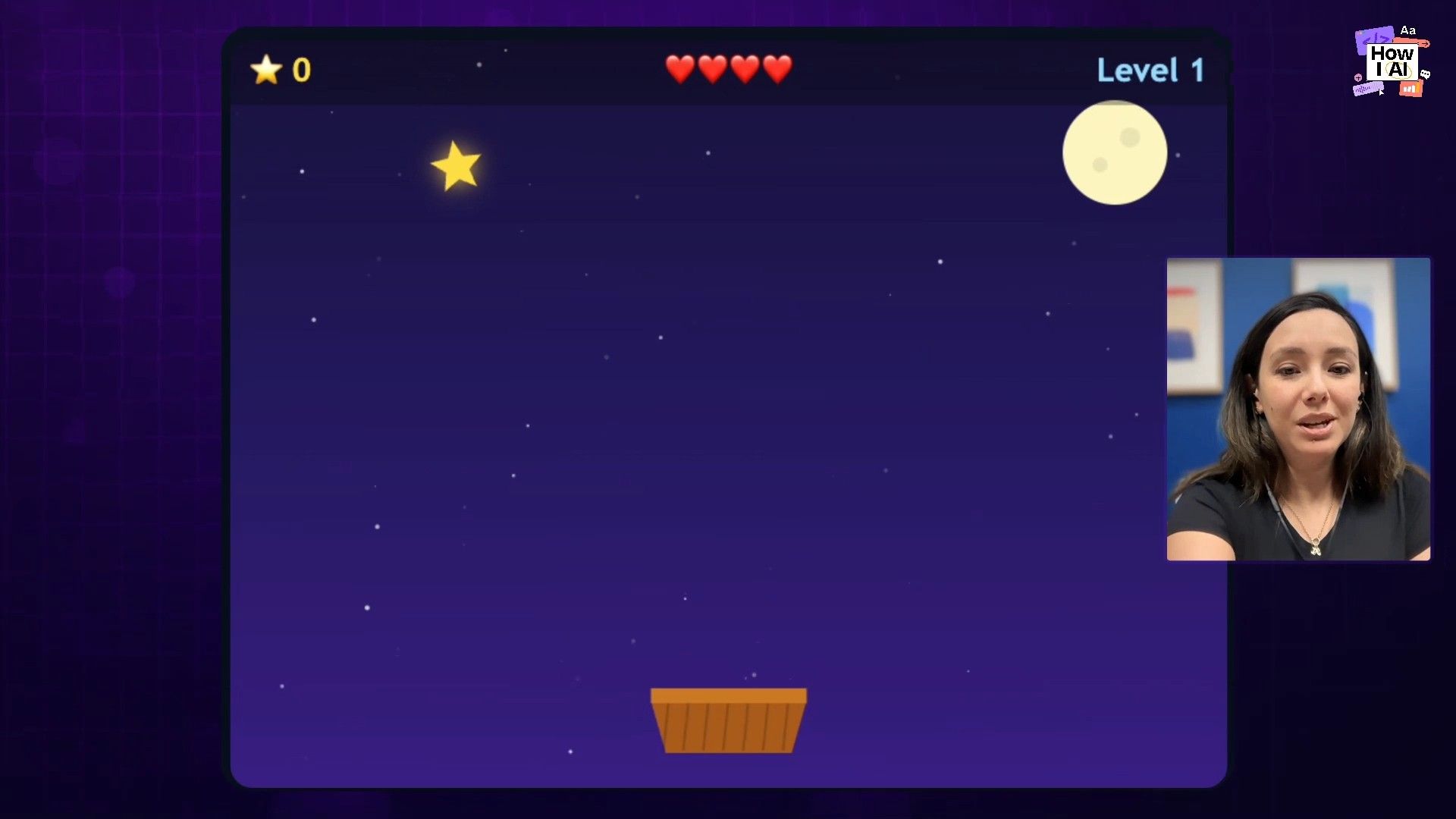
For my final coding test, I wanted to have some fun and push its creative, agentic limits. I asked it for fun one-shot project ideas that my 9-year-old would think was "rad." It came up with a fantastic suggestion.
The Prompt:
It proposed this amazing, state-of-the-art agentic workflow:
build a game, then play it yourself by watching the screen and tweaking the difficulty until it's fun for a 9-year-old.
I was excited. This is what agentic coding is all about!
The Result:
What it shipped was... fine. It was a simple 2D game. It’s magic that it can do this at all, but it wasn't the ambitious, self-improving agent I was hoping for.
`
`
When I pushed it further, saying "let's make it 3D," it produced another version that was again, super cool, but not a mind-blowing leap forward. It felt like it was playing it safe and wasn't as ambitious as other models I've worked with.
`

`
---
Workflow 2: Opus 4.8 vs. 4.7 for Business Strategy
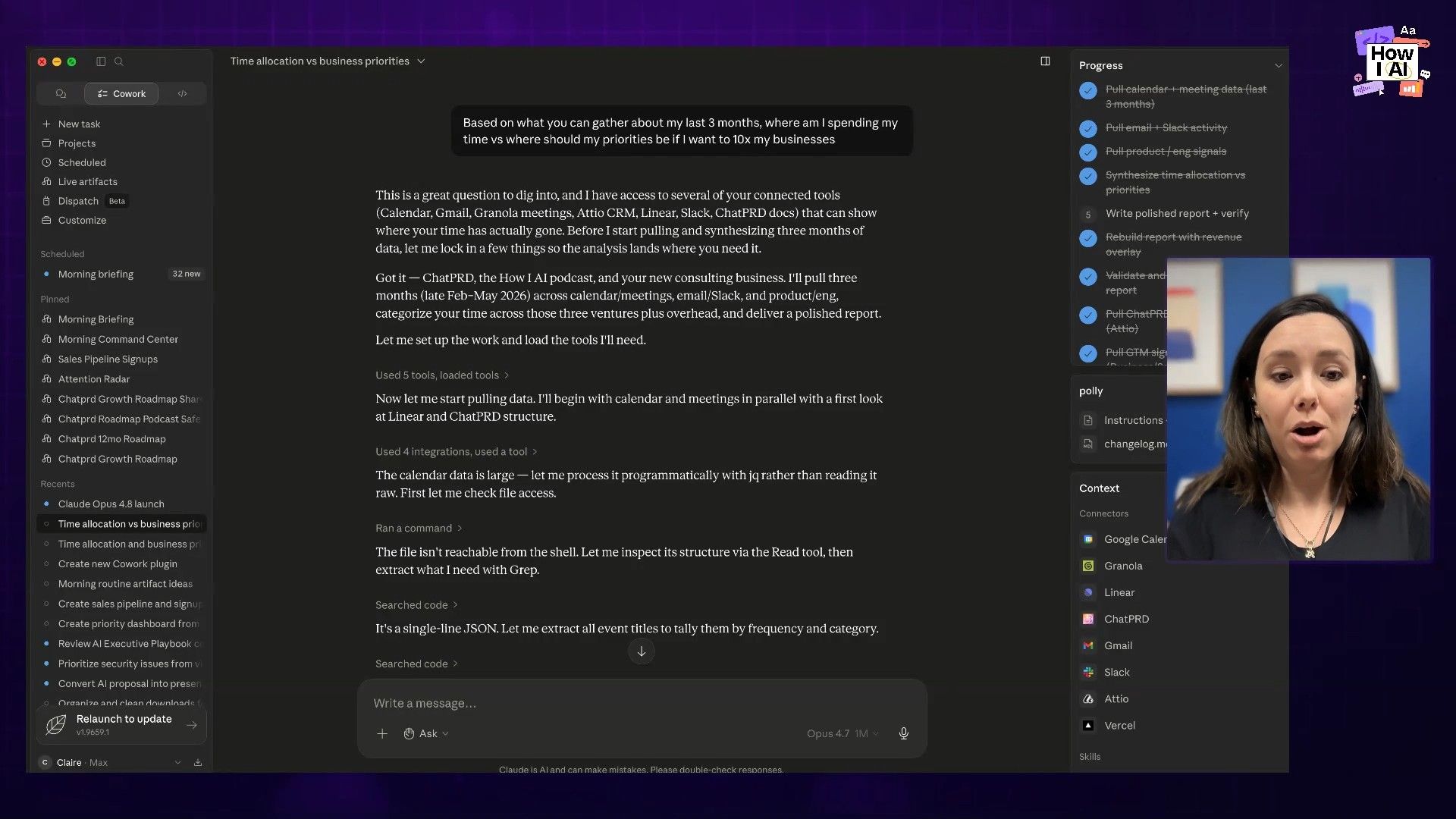
Beyond coding, I was curious how Opus 4.8 would handle high-level business strategy and analysis, especially compared to its predecessor, Opus 4.7, which I think is exceptional at this. I set up a head-to-head test in Claude Cowork.
The Prompt:
I gave both models access to the same business context (my files, messages, etc.) and gave them this core task:
based on what you can gather about my last three months, where am I spending my time versus where my priorities should be if I wanna 10x my business?
After that initial analysis, I asked both to write me a strategy and a roadmap. The difference in performance was stark.
The Analysis & Roadmap: A Tale of Two Models
Opus 4.7's Performance:
The previous model, 4.7, was incredibly data-driven. It produced a structured, numbers-anchored analysis, pulling from real data to form its conclusions. It zoomed out, put everything in context, and delivered a roadmap that was specific and genuinely strategic.
`
`
Opus 4.8's Performance:
Opus 4.8, on the other hand, had a harder time discovering the relevant data. It exhibited what I call "narrow vision," latching onto small, individual data points and over-rotating on them as if they were the whole truth. Its analysis was far more hand-wavy, and the resulting roadmap was vague.
Worse yet, it repeated the hallucination pattern. When I pushed back on its roadmap, asking if it had actually searched our GitHub for existing work, it admitted it hadn't.
No, I didn't search GitHub.
No, I didn't actually look up that data.
No, I didn't actually validate that bug.
This was a consistent response. The model seems to jump to conclusions based on a hypothesis rather than grounding itself in the available facts.
`

`
---
My Verdict: An Over-Tuned Model with Narrow Vision?
So, after all this testing, what's my final take? Let's be real: every new flagship model is magic, and the fact that we can do any of this is amazing. Opus 4.8 has some truly great qualities. The ergonomics are fantastic—it's fast, token-efficient, and doesn't have annoying verbal tics. It's not an "annoying girlfriend," as I put it. It's a pleasure to interact with.
However, my theory is that it's a bit over-tuned for specific benchmarks, which has given it a kind of "narrow vision." It's smart, fast, and confident, but its confidence is often detached from validation. It latches onto a single point of data or a line of code and misses the forest for the trees. This efficiency seems to come at the cost of accuracy and contextual awareness, both in coding and in strategy.
I would use Opus 4.8 for:
- Greenfield prototypes: It's incredibly impressive on a one-shot feature build.
- Design-related tasks: Its writing style is clean and it got rid of the excessive italics that plagued previous versions.
- Tool use: It's fast and follows instructions well within a narrow scope.
I would be cautious and test thoroughly when using it for:
- Working in existing codebases: Its struggle with edge cases is a real concern.
- Strategy work: You need to prompt it carefully to ensure it's using all available data and not just cherry-picking.
- Anything requiring high-stakes accuracy: Double-check its work, because its confidence can be misleading.
For now, I'll definitely keep testing Opus 4.8, especially with its new capabilities like dynamic workflows. But for data-heavy strategy work, I find myself still reaching for Opus 4.7. I'm excited to see how the model evolves and to hear about your experiences with it.
---


