My Honest Review of Claude Fable 5
Anthropic's first Mythos-class model is finally here. I got early access to Claude Fable 5 and tested it across coding, writing, design, vision, and multi-agent workflows. Here's what actually impressed me, what disappointed me, and where this model belongs in your AI stack.
Claire Vo

Mythos Has Arrived (Sort Of)
The model, the myth, the legend…Anthropic's Mythos intelligence class has finally dropped. Well, baby Mythos. We're calling it Fable 5, and this new model is crushing benchmarks. But the question is: can it crush my backlog?
I got early access to the model, and of course I have my own opinions on where it does really well, where it needs a little work, and the question on everyone's mind: does it live up to the terrifying marketing hype?
This review is really going to focus on what the everyday user, what the everyday software engineer is going to think about when they're using this model.
What Anthropic Is Telling Us
Fable 5 is a completely new model class. We had Sonnet, we had Opus, and now we have Mythos, the first of which is Fable 5. It's completely state of the art, exceeding every benchmark Anthropic tested by a significant amount.
Quick pricing note: it's not cheap. $10 per million input tokens and $50 per million output tokens. It's a new tier above Opus. If you're going to use this model, you're going to pay the price.

What Anthropic says it can do that earlier models couldn't:
- Very autonomous — including running days-long, asynchronous tasks
- An engineer's engineer — and that's both the upside and downside I experienced
- Proactive — it doesn't wait for you to spell everything out
- Exceptionally good at vision — this is where I actually really loved the model
- Built for effort — it works hard, builds harder, verifies more
But there's a catch: it consumes tokens at about 2x the rate of other models. This is a big boy model.
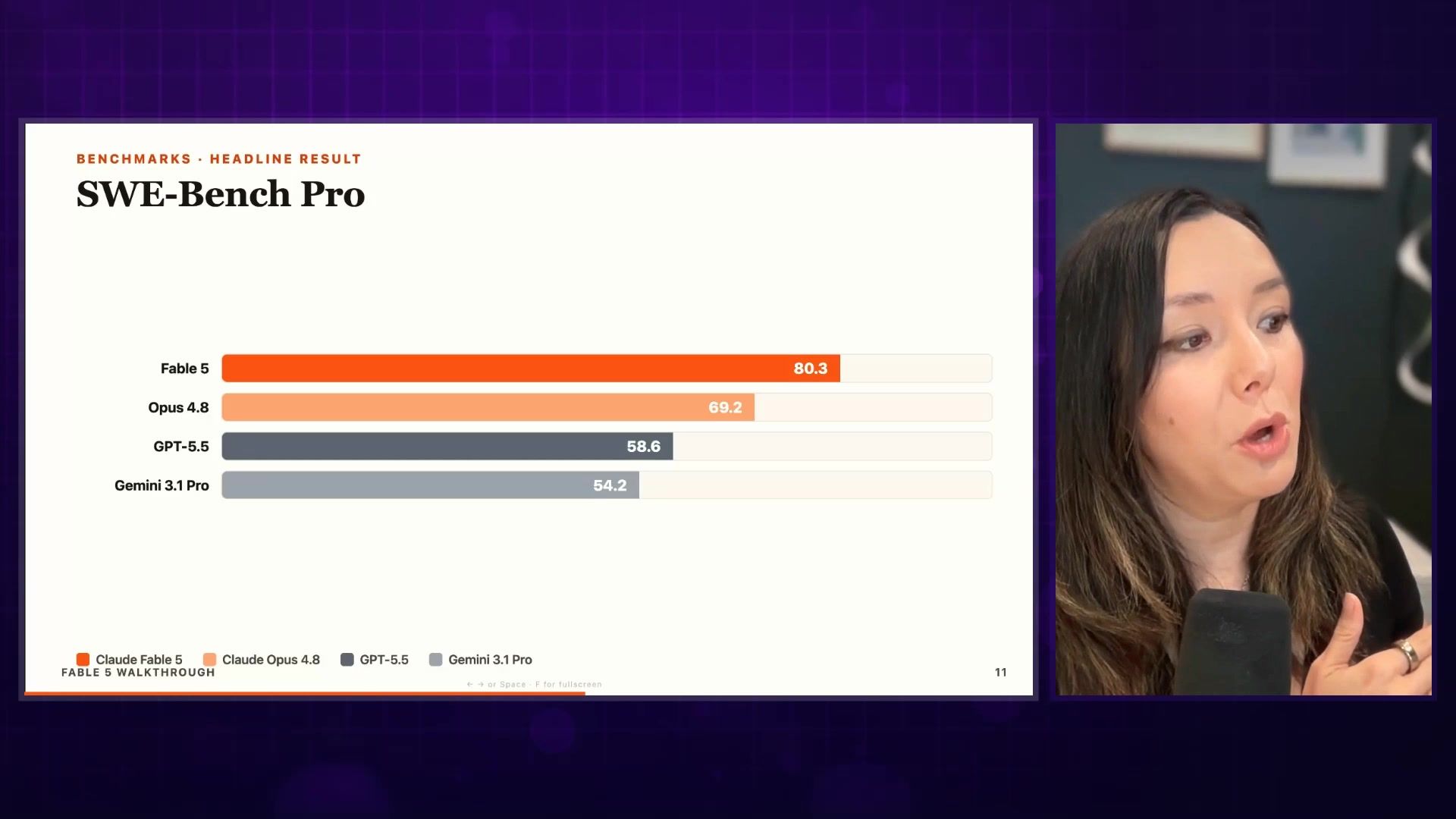
Crushing Benchmarks — 80.3% on SWE-Bench Pro
Look at these numbers. Fable 5 compared to Opus 4.8, GPT-5.5, and Gemini 3.1 Pro:
- Fable 5: 80.3% on SWE-Bench Pro
- Opus 4.8: 69.2%
- GPT-5.5: 58.6%
- Gemini 3.1 Pro: 54.2%
Significant increase, very far ahead of these other models. While I wasn't testing the most advanced use cases, I didn't find something that technically it failed at. These benchmarks have outperformed across the board — this is Anthropic's state of the art model.
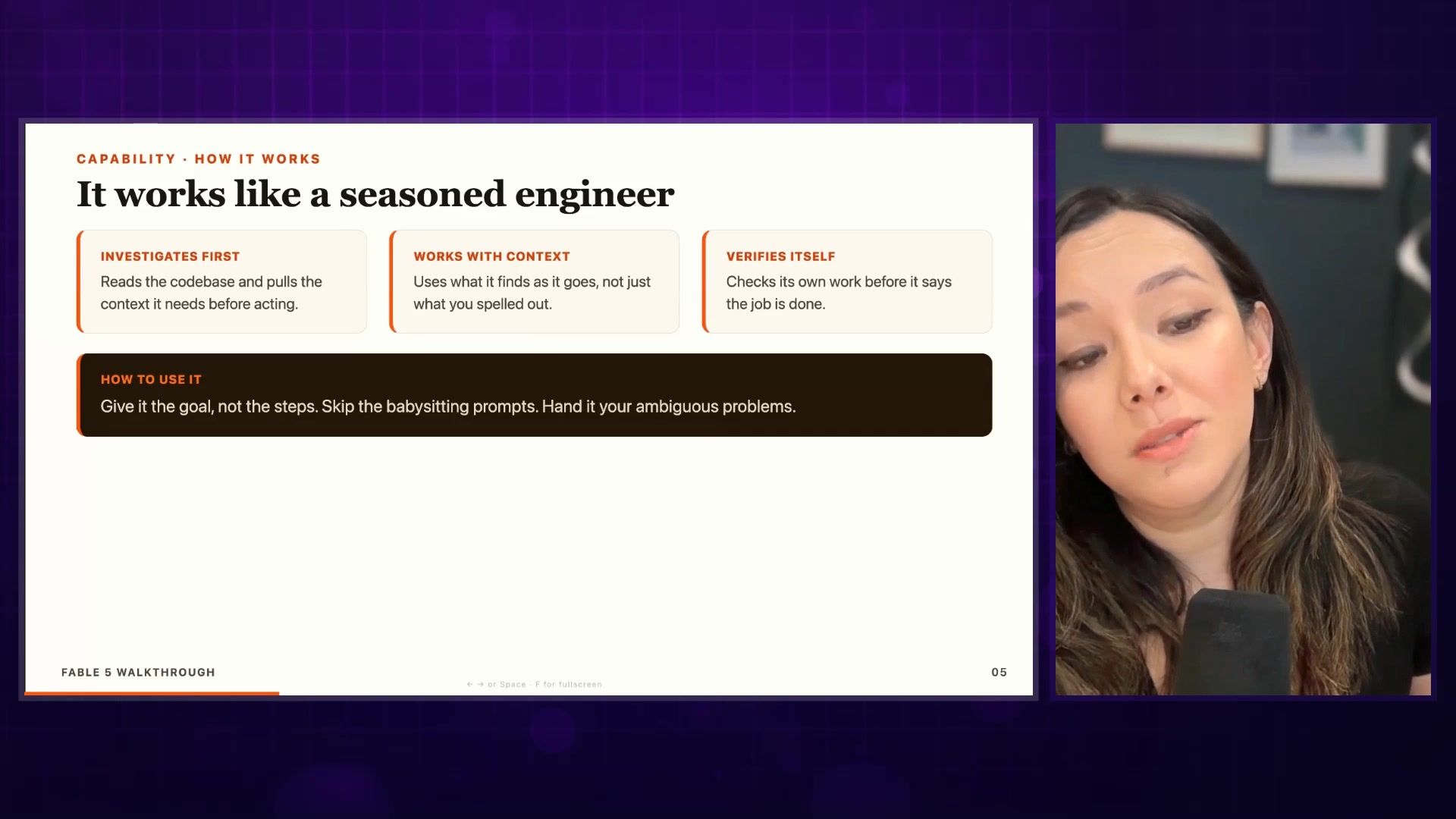
The Seasoned Engineer Problem
They explicitly say that Fable works like a seasoned engineer. Unfortunately, if you've worked with a seasoned engineer, you know there's good to this and bad to this.
It is very complete in its investigation. It's definitely going to go search out all the corners. It's definitely going to think about how it can be 120% sure that it's shipping the right thing. But guess what? That's not always in service of launching. And honestly, that's not always in service of building a great product.
Product manager talking — even engineer talking — sometimes you want it to be a little bit dumber.
I used extra high effort level for most of my tasks. I didn't want anybody in the comments saying "Claire, you picked high for this task and it should have been extra high." I used all the brains of Fable. But it is very, very token intensive. My question for any of these models: does this token intensity actually output the right results?
Safeguards and the Fable vs. Mythos Distinction
There are specific classifiers in this model for cybersecurity, biology, chemistry, and distillation. They don't want anybody doing bad stuff in these categories with this very intelligent model.
What's nice about how they've implemented this: they have a new fallback concept. If you get classified into one of these categories, instead of hard blocking you, it falls you back to Opus 4.8. This graceful fallback is also available as an optional parameter in the API.

Fable vs. Mythos — what's the difference?
- Fable = has the safeguards, available in general availability for all of us
- Mythos = no safeguards, restricted to Project Glasswing enterprise partners
- They are fundamentally the same underlying model
95% of sessions on this model did not hit a fallback. I don't believe I hit one, but again, I'm not doing anything in cybersecurity, biology, or chemistry. Yet.
Co-Launches Worth Knowing
Three things shipping alongside Fable 5:
- Claude Managed Agents — going into public beta. Anthropic's hosted harness for running long-running agentic work. Fable ships out of the box in Managed Agents.
- Advisor Strategy — use Fable 5 as a senior advisor and cheaper models as the execution layer. Works today in the API and in Claude Code.
- Fallback API — an optional parameter on the Messages API that allows blocked requests to continue using Opus 4.8 at Opus pricing.
Where It Actually Impressed Me: Vision and Document Formatting
So what is it actually like to use? I ran Fable 5 on a bunch of different work.
Vision is where it really shines. I've been making handwriting practice documents for my 7-year-old based on classic texts and poems. Comparing Mythos 5 to Opus 4.8 on PDF formatting—Mythos 5 did a much better job. The right spacing, very clear to read, enough white space. The Opus version was dense with hard-to-read lines.
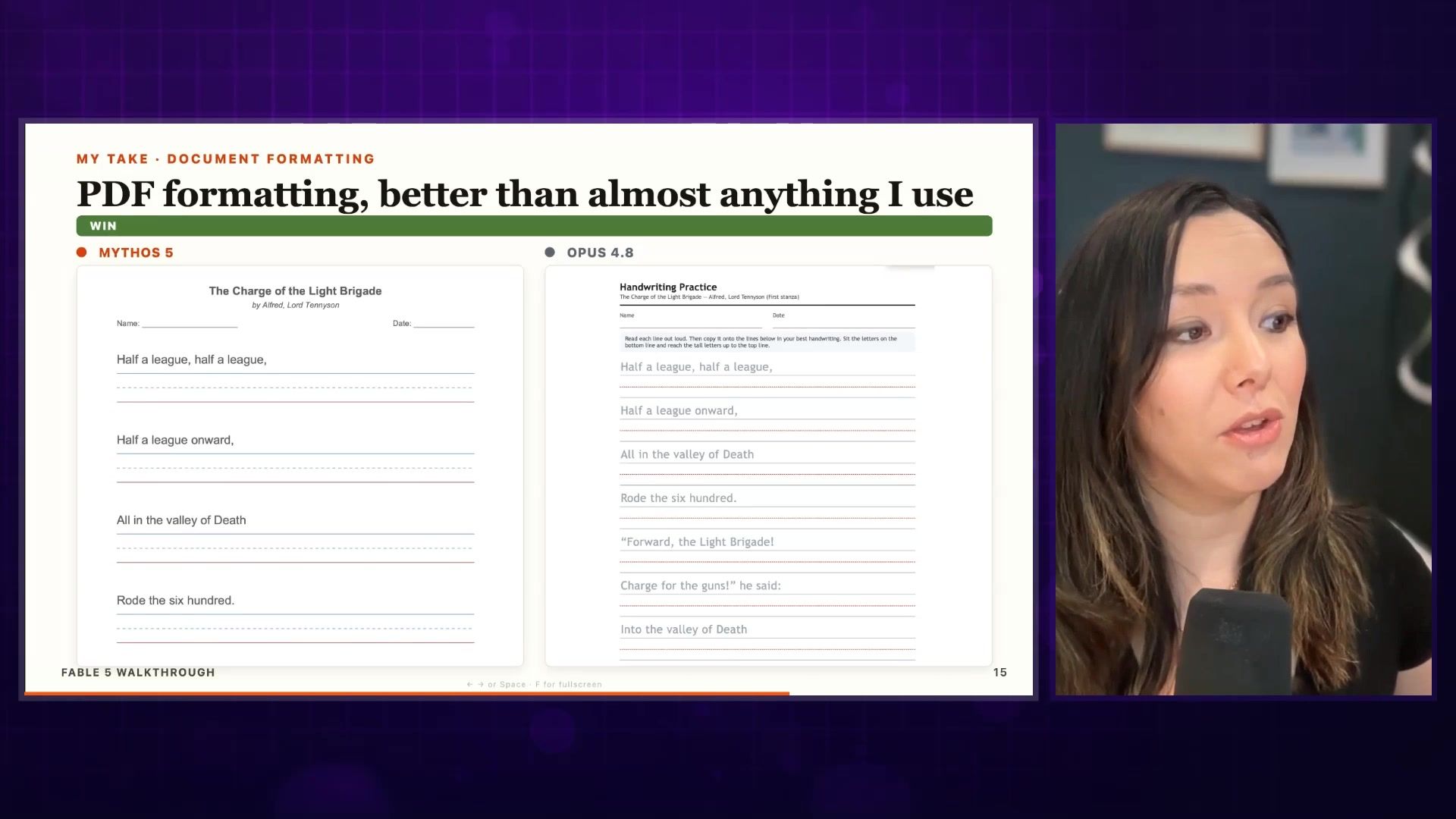
Simple eval for me, but a very good one. If you need PDF formatting, document parsing, or anything vision-related, this model really excels.
Where It Disappointed Me: Writing Quality
The writing is nearly unreadable. If you're thinking about Mythos for prose, for spec writing, for PRDs, maybe think again. This is writing by agents for agents.

I had Fable 5 do an adversarial review of my product graph requirements for ChatPRD. It gave me this markdown document that looks very long and intelligent, but if you actually read through it, it's just really hard to parse. Internal references, very detailed, but not in a way where you can zoom out. These big blocks of paragraphs... it is just really hard to see the forest for the trees.
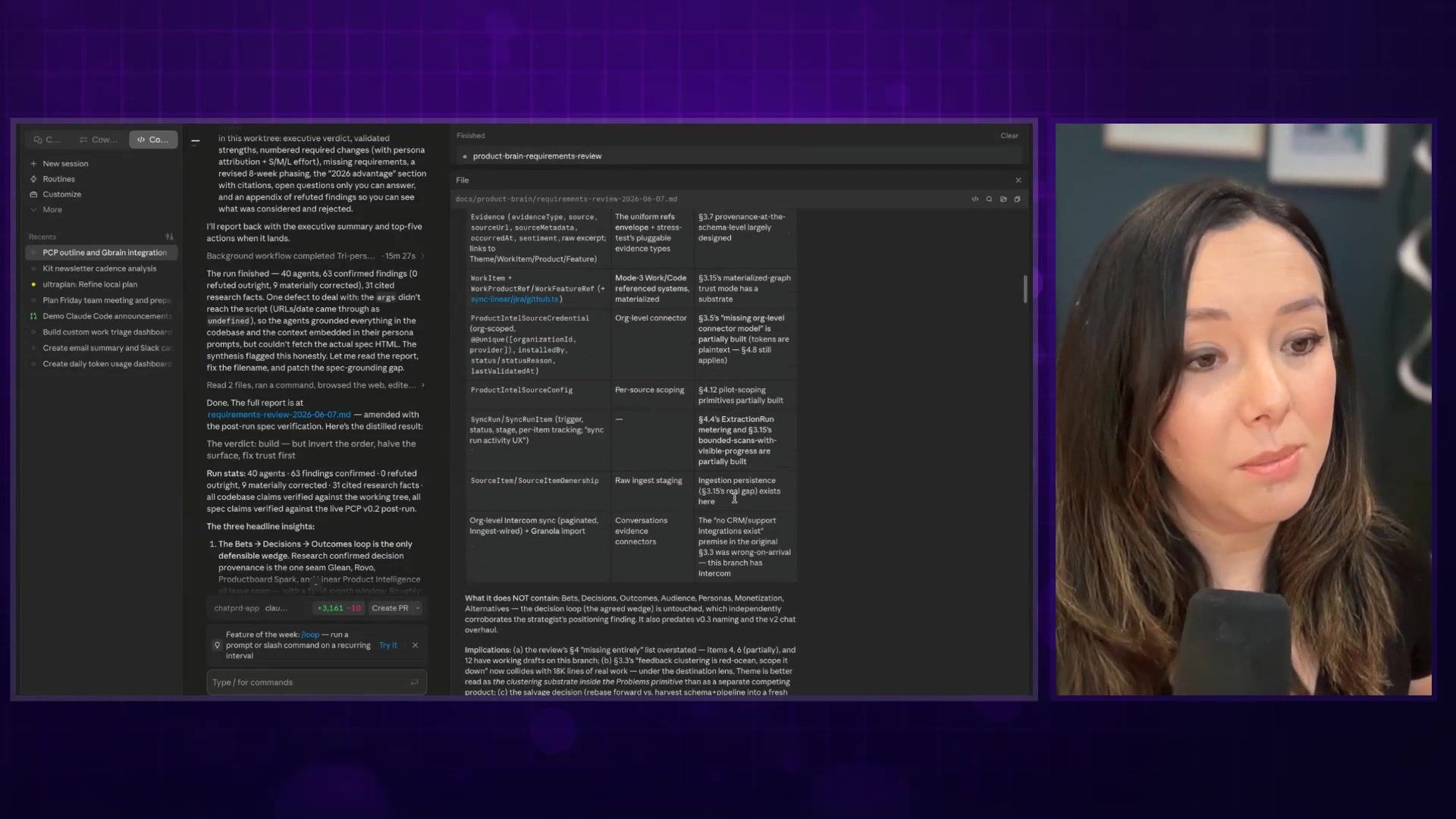
I would actually suggest pulling back to a Sonnet or Opus model for specs, and then looking at Fable as an orchestrator of execution.
Terrible at Design
The other thing that shock, shock, shocked me was how legitimately terribly bad it was at design. At least at one-shot design. I asked Fable to design a skills registry and man alive, did it do a poor job. I'm not even talking AI-slop bad, what I saw was fundamentally terrible design. Gray, black, red, simple outlines.
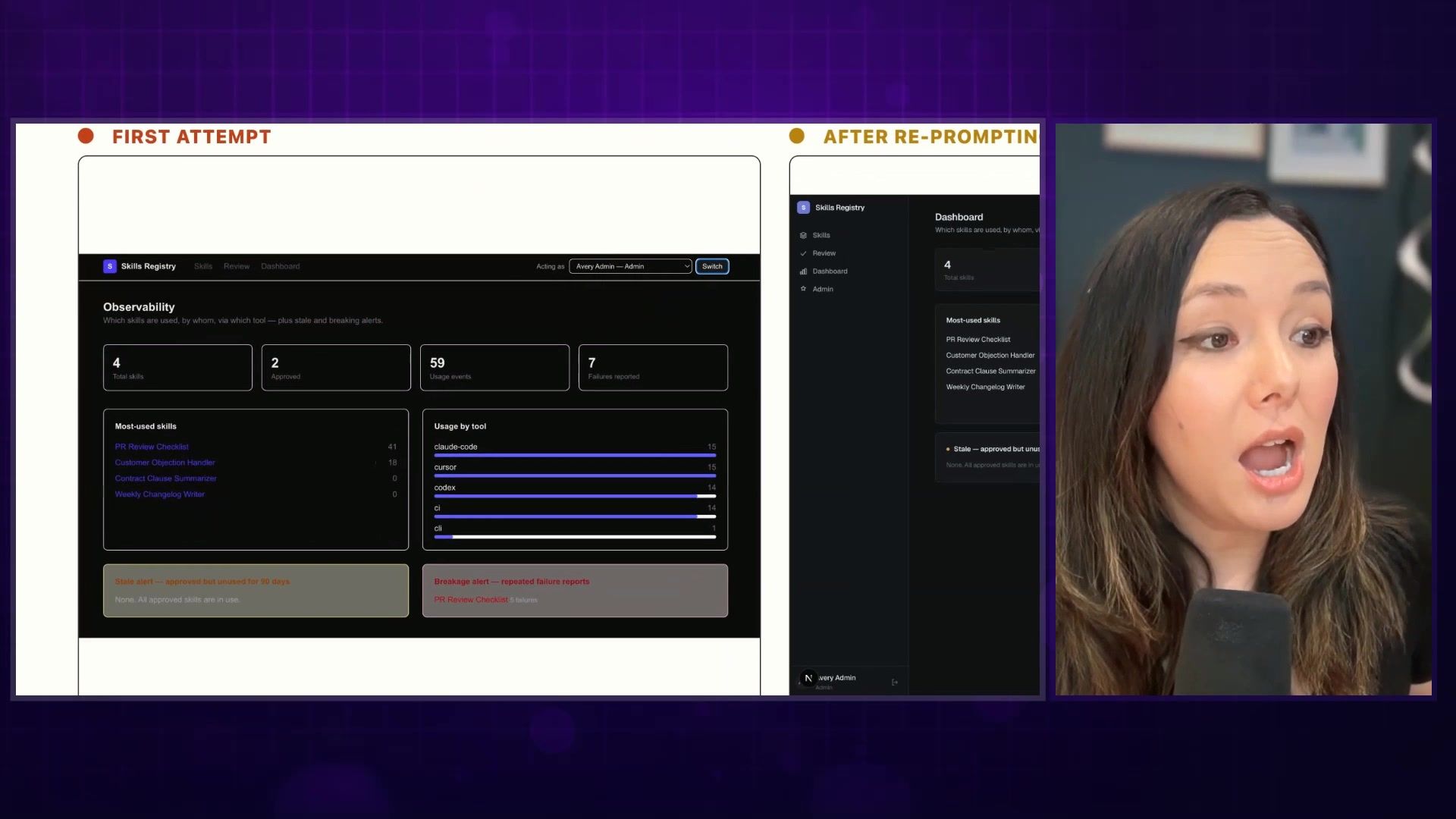
The Anthropic team suggested I just needed to be more detailed in my prompting. I've never had to do this before in the last year of models in terms of frontend. Even when I prompted it with more detail, it was still not very impressive design.
You might want to toss Opus in the mix instead of relying on Fable for design.
Conservative on Execution
When I tried doing ambitious, days-long work (ex: I took a spec and said "ship the V0 of this, the MVP, enough that a customer could get value") it really took minimal to heart. Very, very narrow. Not actually that useful.

I'm curious if this comes from the safeguards on this model. It's been a challenge I've seen since the later Opus models; they're not super ambitious. You'll have to think about how to prompt this to get long-running outcomes paired with the right product ambition.
Multi-Agent Workflows: Promising but Buggy
I really doubled down trying to test Claude's dynamic workflows and subagent designs. The multi-agent capability is definitely there, and I had some successful multi-agent runs kicked off in Fable. But I also ran into a lot of stalls and errors.

I made the mistake of walking away from my laptop and came back to subagents that had stalled after about three hours. I really want to see how the Claude Code model holds up to the promise of multi-agent orchestration. I had some successes and some bugs. I think this is a Claude Code issue, not necessarily a model issue—but with this promise of long-running, days-long prompts, you really need to deliver technically on the outcome.
My Takeaway: Hand It Your Hardest Problems

Where to use Fable 5:
- Hard technical problems - not cybersecurity, bio, or chemistry, but complex engineering work where detail matters
- Vision problems - document formatting, PDF parsing, anything where you want something to look good
- Long-horizon work where thoroughness outweighs speed
Where to skip Fable 5:
- Frontend work and design - the output was disappointing
- Strategy or spec work - it overthinks things, the prose is nearly impossible to parse
- Quick, scrappy MVPs - it's too conservative on execution
It definitely has a place in your stack. If you want to learn more, definitely look up the prompting guide for Fable. It's going to repeat a lot of what I said: hand it your hardest problems, know what this model is good for and what it's not, and how to get a good outcome.
Mythos is here. I cannot wait to hear what you build, what you overbuild, and what you make ugly with this new model.
Thanks for joining How I AI.


