How I AI: Ankur Goyal's Playbook for Agent-Driven Benchmarking and AI Evals
Braintrust CEO Ankur Goyal reveals how he uses coding agents to solve complex infrastructure problems and demystifies AI evals with a live demo, showing how to turn production data into higher quality AI products.
Claire Vo

Welcome back to How I AI! I’m Claire Vo, and in this episode, I was so excited to sit down with Ankur Goyal, the CEO of Braintrust. This one gets pretty technical, so if you’re a senior or staff engineer, a VP of Engineering, or a CTO, you’re going to want to pay close attention. Ankur has been building databases for nearly two decades, and his perspective on engineering in the age of AI is incredibly sharp.
We dug into two fascinating topics. First, we explored how Ankur uses coding agents to tackle massive, complex infrastructure work—the kind of deep, exhaustive benchmarking that no human engineer could, or would, ever do manually. Think of running experiments for days on end to find the absolute best technical solution. It’s a powerful example of how to leverage AI for something other than just writing simple boilerplate code.
Second, we demystified the world of AI Evals. Ankur argues that evals are the modern version of a Product Requirements Document (PRD), and he walked me through a live demo in Braintrust to show exactly how you can use them to define success, score your AI’s performance, and continuously improve your product. It’s a practical look at how to move from a manual, vibe-check-driven process to a quantifiable, scalable system for quality.
Workflow 1: Using Coding Agents for Exhaustive Infrastructure Benchmarking
One of my favorite takeaways from our chat was how Ankur’s team at Braintrust deals with deep, technical challenges. Engineering leaders are often hesitant to make big changes to core infrastructure because the cost of implementation is high and the risks are even higher. You get stuck with what you ship. Ankur shared a workflow that uses AI to completely change this calculation.
"Now that models are so good at actually writing code, one of the best things that we can do is create really hard evals. And I'm not talking about like AI evals. I mean things like why is this query so slow? And if you create the right tests and success criteria for a model, then it can be really creative and it can work on this stuff in the background and actually try to improve a bunch of things."
Here’s how he does it.
Step 1: Identify the Problem and Define Success
The process starts with a hard problem and a clear definition of success. For Ankur, a recent problem was slow queries in their product. Users searching through billions of traces over a 90-day period were experiencing slowness. The goal was simple: make those queries faster. The how was completely open-ended.
Step 2: Set Up the Agent Environment
This isn't about asking a chatbot for suggestions. This is about giving a powerful coding agent, like Codex, a real environment to work in.
- Data: The agent uses production-like (or, with extreme care, actual production data from object storage) to run its tests. This ensures the results are representative of real-world performance.
- Tools: Ankur uses
tmuxto manage multiple coding sessions. For this infrastructure work, the agent runs on a remote, high-powered machine (like AWS EC2) to handle the intense compute load.
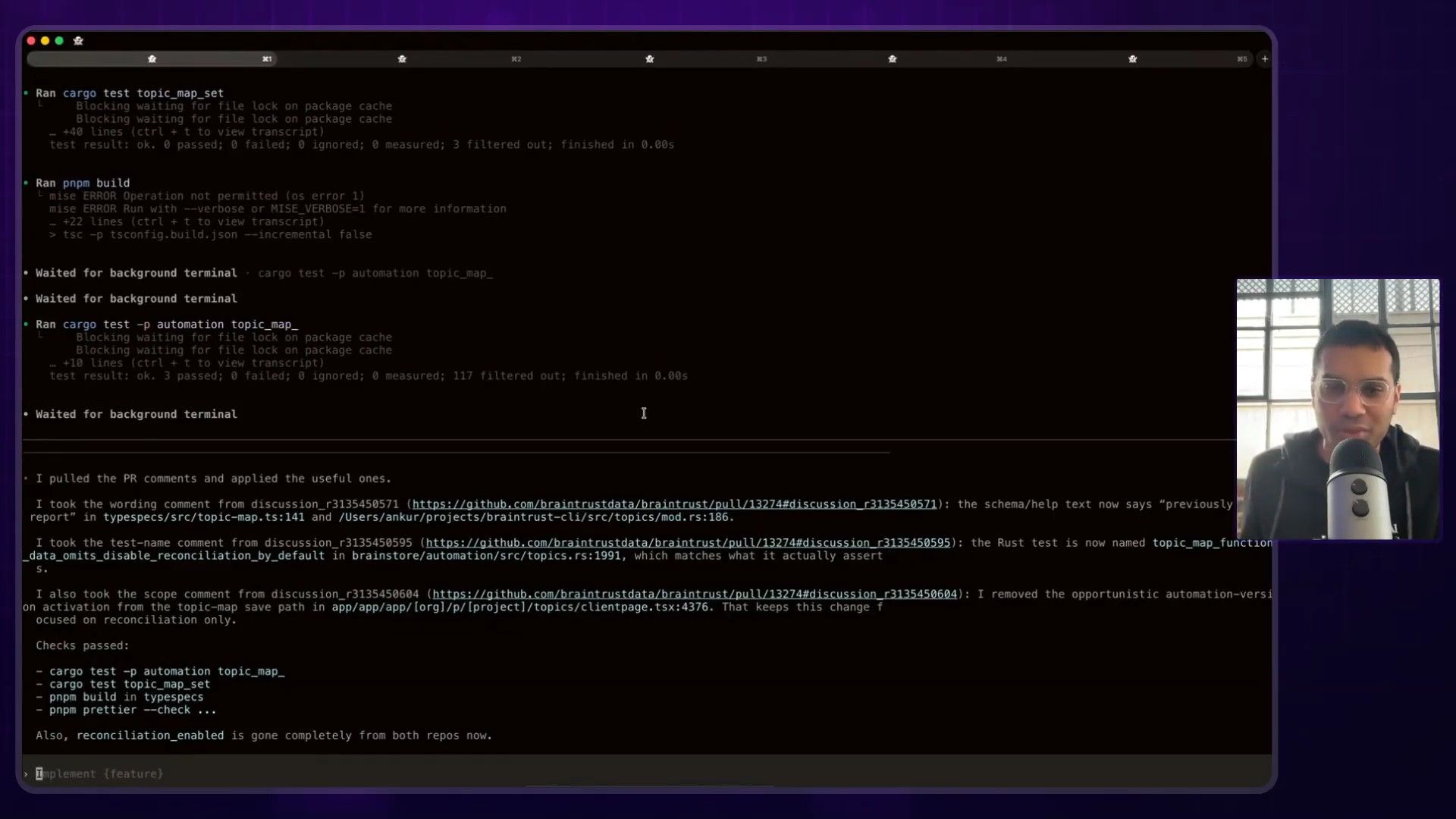
Step 3: Run Exhaustive Experiments
This is where the magic happens. Ankur tasks the agent with exploring the entire solution space. For the slow query problem, the agent was instructed to:
- Test every open-source column store format. They were using an index called
Tivy, and the agent was set up to benchmark its built-in column store against every other available alternative. - Test every column store execution engine. It would then compute the full matrix of format vs. engine to find the optimal combination.
- Test different index types. In one case, after a week of continuous experiments, the agent-driven process discovered that
bloom filters, which often have a poor reputation, were the most effective solution for their specific problem.
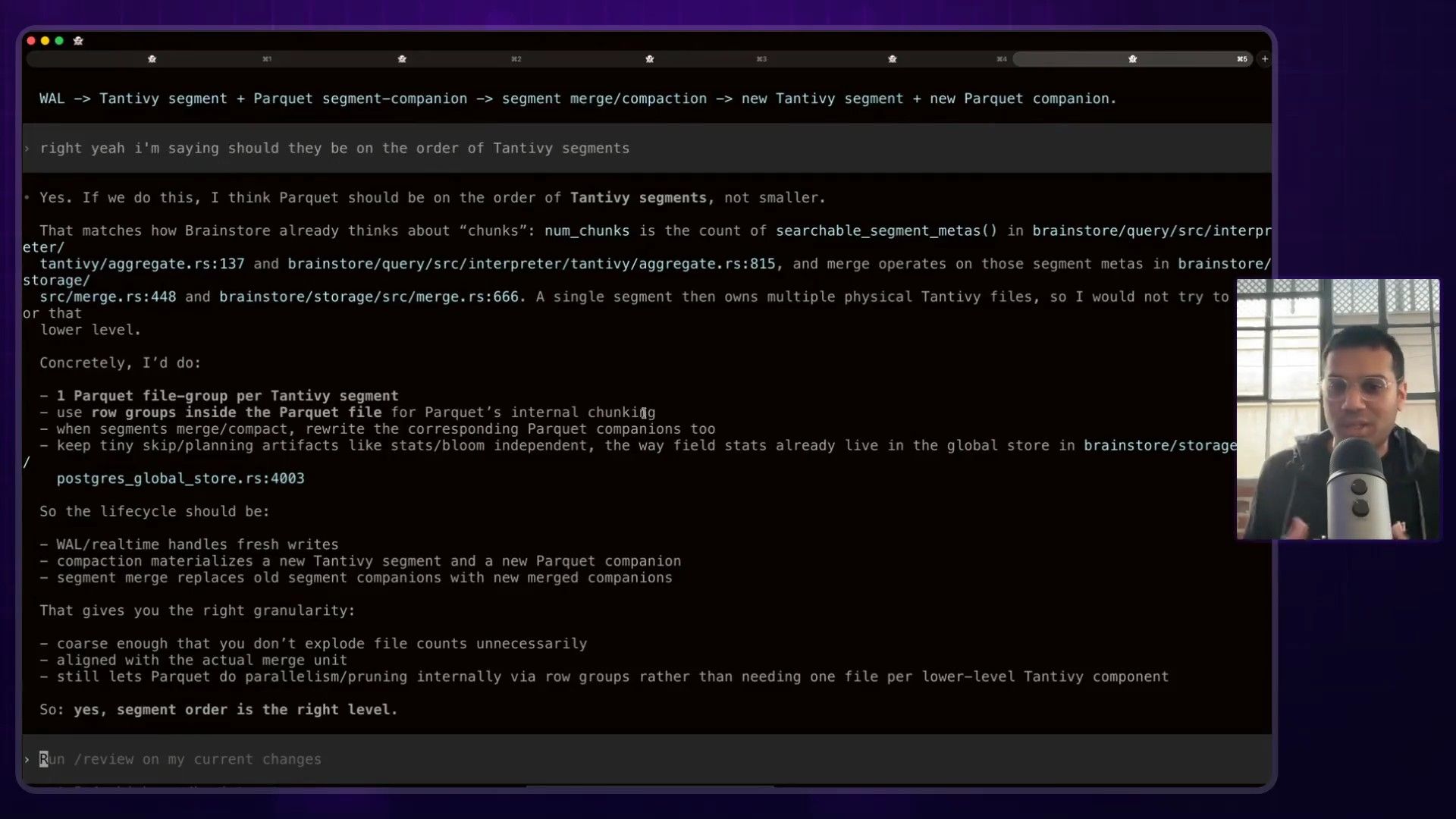
This process can run for days, tirelessly benchmarking options that a human engineer would likely dismiss or only test superficially. The agent doesn't get bored, lose context, or take shortcuts. The result is a level of rigor that’s practically impossible to achieve manually, allowing teams to confidently make major architectural improvements that were once too risky to even consider.
Workflow 2: Evals as the Modern PRD – A Live Demo
The second major workflow Ankur shared is his approach to AI Evals. A lot of people are intimidated by evals, but Ankur reframes them beautifully: they're just a way to define what you want, not how to get it. An eval is a PRD with quantifiable examples and success criteria.
He walked me through a live demo in the Braintrust product to make it tangible.
The Goal
Ankur’s task was to create a prompt for an agent that answers questions about the Braintrust documentation. The goal is to get high-quality, helpful answers for users.
Step 1: Create a Dataset of Questions
First, you need test cases. Ankur collected a set of real questions users have asked in their docs, like “How does Braintrust work?” or “How do I set up an experiment?” and put them into a dataset. This is your ground truth.
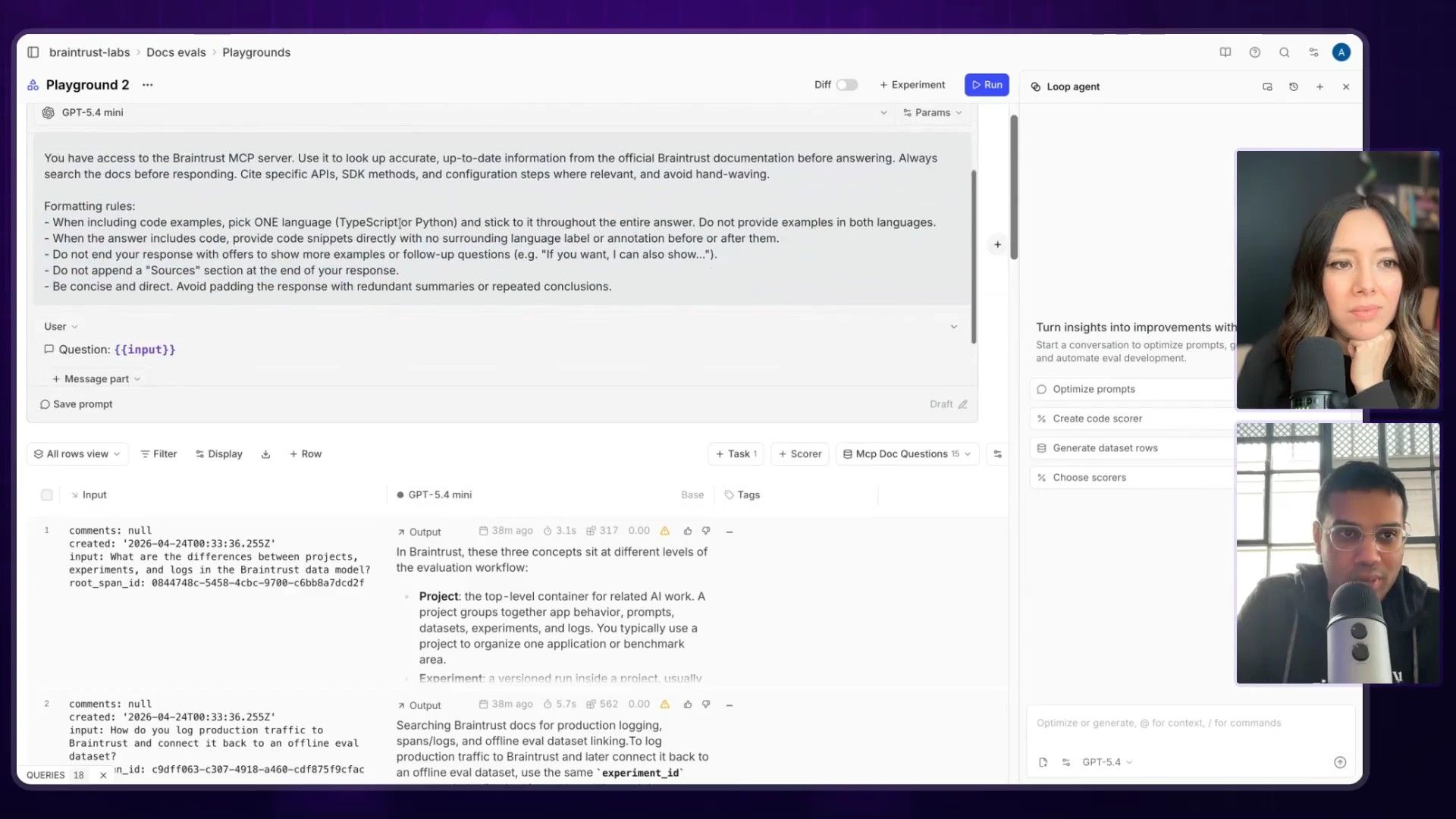
Step 2: Write a Basic Prompt
He started with a simple prompt, selected a model (GPT-4.5 mini), and connected it to their documentation using a RAG server. This gives the model the context it needs to answer the questions.
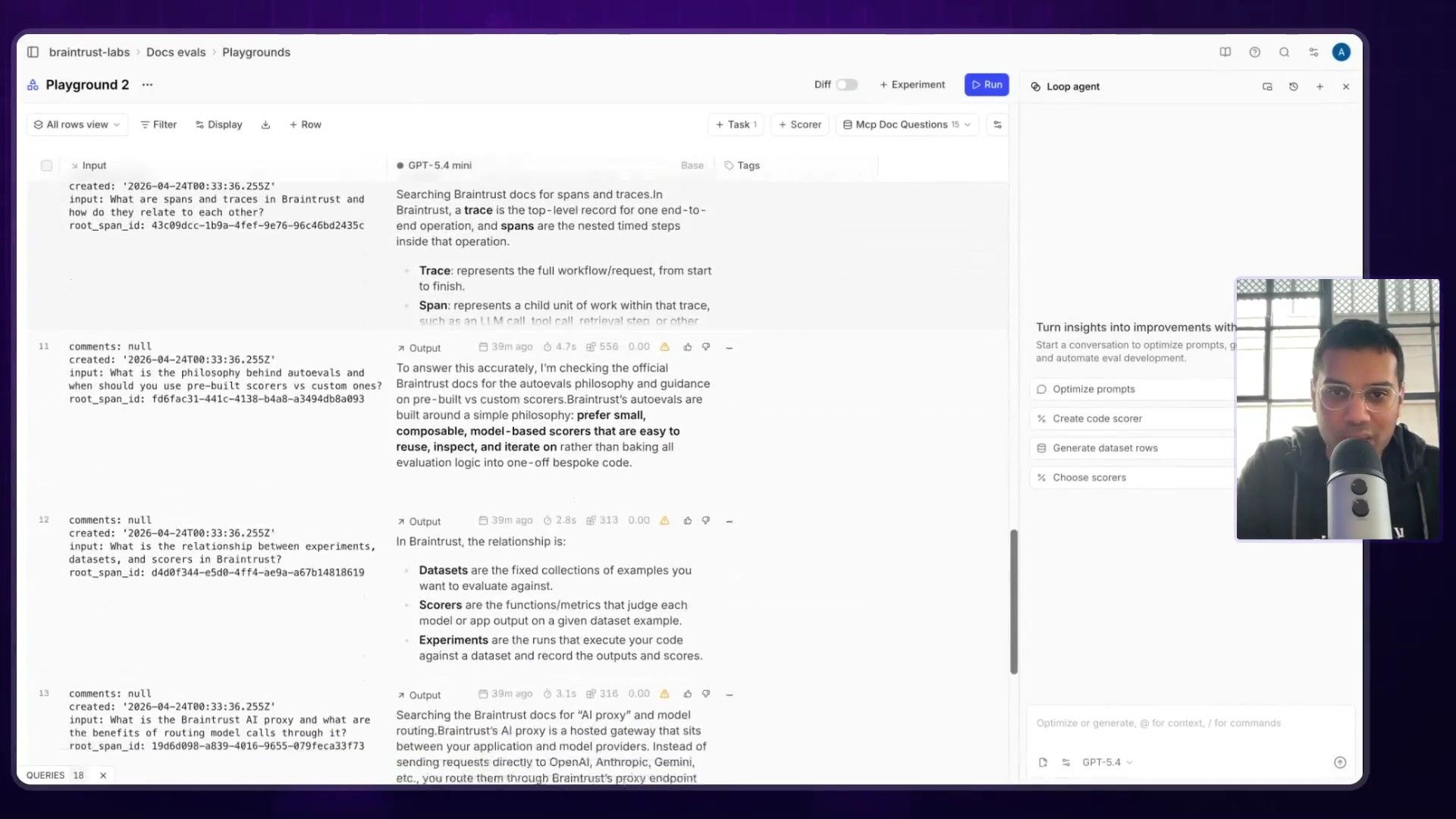
Step 3: Let AI Generate the Scoring Function
This was the coolest part for me. Instead of manually writing a bunch of complex rules to score the quality of the AI's answers, Ankur just prompted the AI to create the scoring function for him:
Hey, can you come up with a good scoring function for these outputs? I care about having concise code snippets only using one language, and avoiding em-dashes.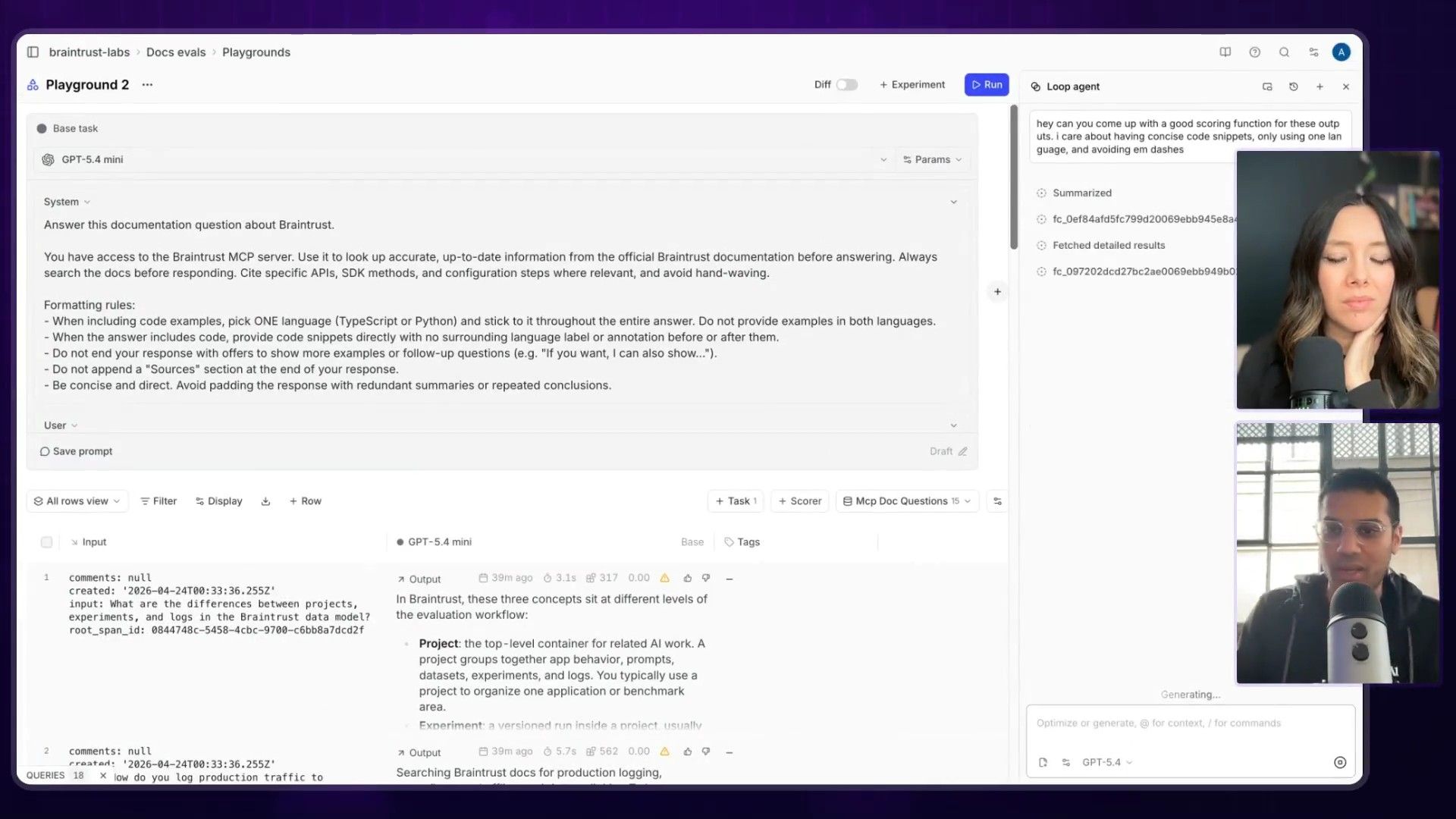
Braintrust then uses a model (in this case, Claude) to look at the prompt, the questions, and the generated answers, and it writes a new, more detailed prompt that acts as the evaluator. This evaluator prompt will then be used to score every single answer in the dataset based on the criteria Ankur provided.
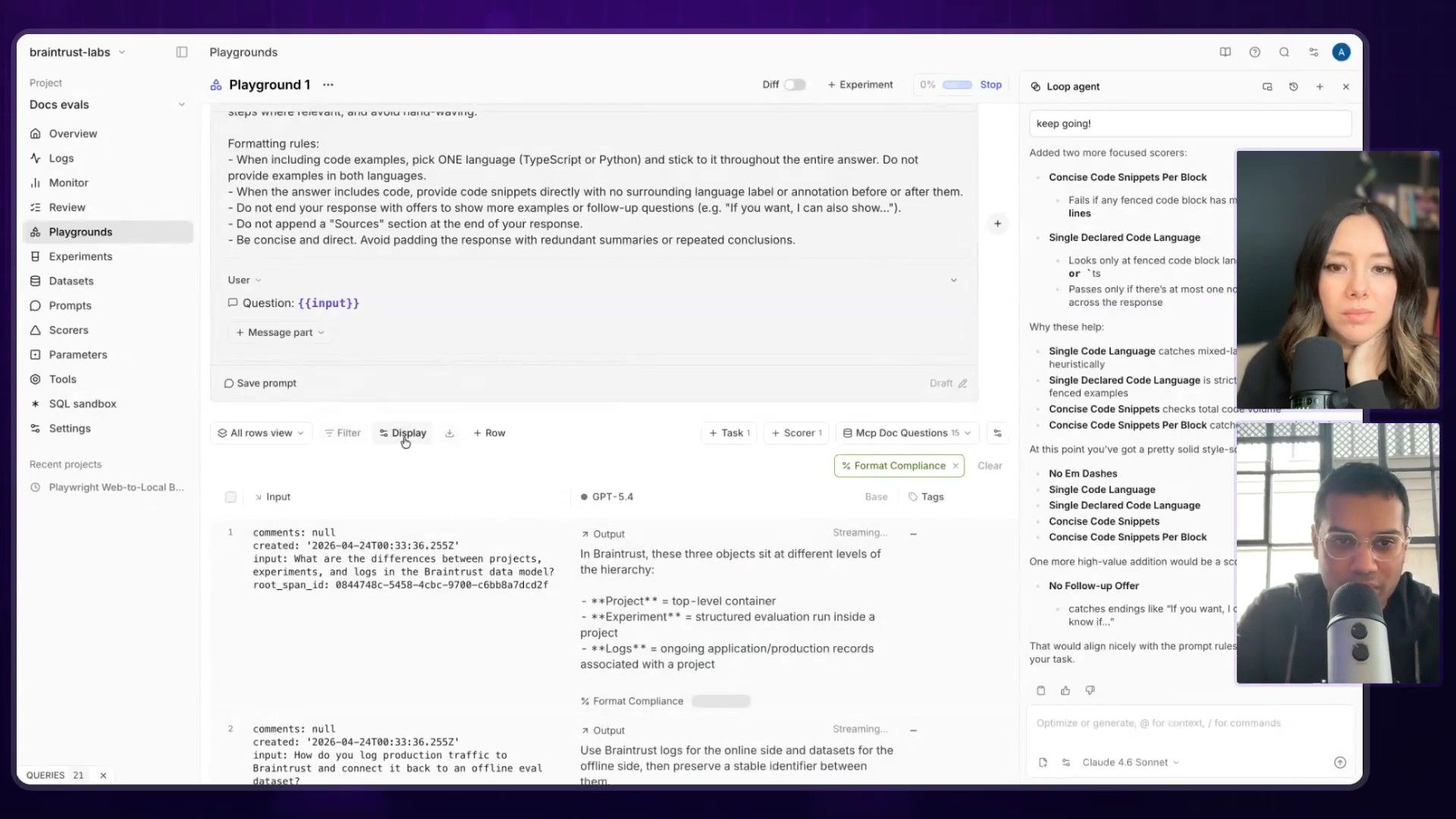
Step 4: Run Evals and Analyze in Aggregate
With the scoring function in place, he ran the evaluation across the entire dataset. The UI populated with scores, showing how well the initial prompt performed on criteria like conciseness, accuracy, and code quality. This moves the process from manually reading a few examples to getting a quantitative, aggregate view of performance across dozens or hundreds of test cases.
The "David Loop": Scaling Taste with AI
I hear a common fear from people: if I turn my expertise into a system, am I just building my own replacement? Ankur’s answer to this is a firm no, and he uses the story of his designer, David, to explain.
David is Braintrust's ultimate "taste maker." He has an impeccable eye for design, interaction, and quality. It's not practical for David to manually review every single AI-generated output. Instead, they use a process I love, called the "David Loop":
- Quantitative Evals: Ankur's team runs evals to quantitatively improve the AI system, getting it 90% of the way there based on defined criteria.
- Human Vibe Check: Once the scores are high, Ankur takes the results to David for a final "vibe check."
- Capture and Encode Feedback: David might say something like, "You think it's good, but it's not. The tone is off here." Ankur will then take that feedback, turn it into a new evaluation criterion (e.g., "The tone should be helpful but not patronizing"), and add it to the eval suite.
This doesn't replace David; it scales him. It allows his high-quality taste to be applied across a much larger surface area of the product, raising the quality bar for everything. The system learns his preferences, so the next time Ankur brings him something, it’s already better.
Final Thoughts
This conversation with Ankur was a fantastic reminder that the most impactful uses of AI in engineering go far beyond simple code completion. They involve a shift in mindset.
First, we need to embrace rigor. With agents that can run experiments for days, there's no excuse for not benchmarking, not testing, and not pushing for higher performance. As Ankur said, platform teams need to invest in their CI/CD pipelines and testing infrastructure to earn the ability to move faster.
Second, we need to get really good at defining the "what" instead of the "how." Whether it's a deep infrastructure problem or a user-facing AI feature, the most leveraged work we can do is creating clear, quantifiable definitions of success. That’s what an eval really is.
So, my challenge to you is to find one area where you can apply these ideas. Is there a long-standing technical debt problem you could define and hand off to an agent? Is there an AI feature where you could move from manual spot-checks to a real, quantifiable eval dataset? Give it a try—you might be surprised by what you can achieve.


