How I AI: Hamel Husain's Guide to AI Quality with Error Analysis and Claude Workflows
Learn how AI expert Hamel Husain uses a systematic error analysis framework to debug AI products and how he runs his entire business using Claude projects and a GitHub mono-repo. This episode provides actionable steps to move from 'vibe checking' to data-driven quality improvements.
Claire Vo
As a product leader who’s been building in tech for a long time, I can tell you that building with AI is a completely different beast. We’re working with non-deterministic models, and as product people, we're suddenly on the hook for making sure their outputs are high-quality, consistent, and reliable. It’s a huge challenge, and one that often feels like we're just “vibe checking” our way to a better product.
That’s why I was so excited to sit down with Hamel Husain. Hamel is an AI consultant and educator who brings some much-needed structure to this messy new world. He helps demystify the process of improving AI products, pulling us away from guesswork and into a data-driven framework. He’s worked with clients like Nurture Boss to take their AI assistants from pretty good to actually great, and he shared his exact playbook with us.
In our conversation, Hamel walks us through two of his core workflows. First is his step-by-step error analysis framework, a process any product team can use to systematically find, categorize, and fix the most critical failures in their AI system. Second, he gives us a look at how he runs his entire consulting business using a combination of specialized Claude projects and a single GitHub mono-repo as his 'second brain.'
If you're building an AI product and feel like you're just tweaking prompts and hoping for the best, this post is for you. Hamel's methodical approach is exactly what you need.
Workflow 1: From 'Vibe Checking' to Systematic Error Analysis
The most uncomfortable feeling when scaling an AI product is uncertainty. You fix one prompt, but did you break something else? Are you actually improving the overall quality, or just guessing? Hamel’s first workflow is the perfect antidote to that feeling, offering a structured process for identifying and prioritizing the most impactful issues.
“It has an immense quality. It's so powerful that some of my clients are so happy with just this process that they're like, that's great, Hamel, we're done. And I'm like, no, wait. We can do more.”
Step 1: Log and Review Real User Traces
The foundation of any good improvement process is looking at real data. As product managers, we're used to writing SQL or analyzing metrics, but with AI, our 'data' is often a bunch of messy, unstructured conversations. The first step is to capture these interactions as traces—a complete log of a user's conversation with your AI, including system prompts, user inputs, tool calls, and final outputs.
For his client Nurture Boss, an AI leasing assistant for property managers, Hamel used tools like Braintrust and Arize Phoenix to log and visualize these traces.
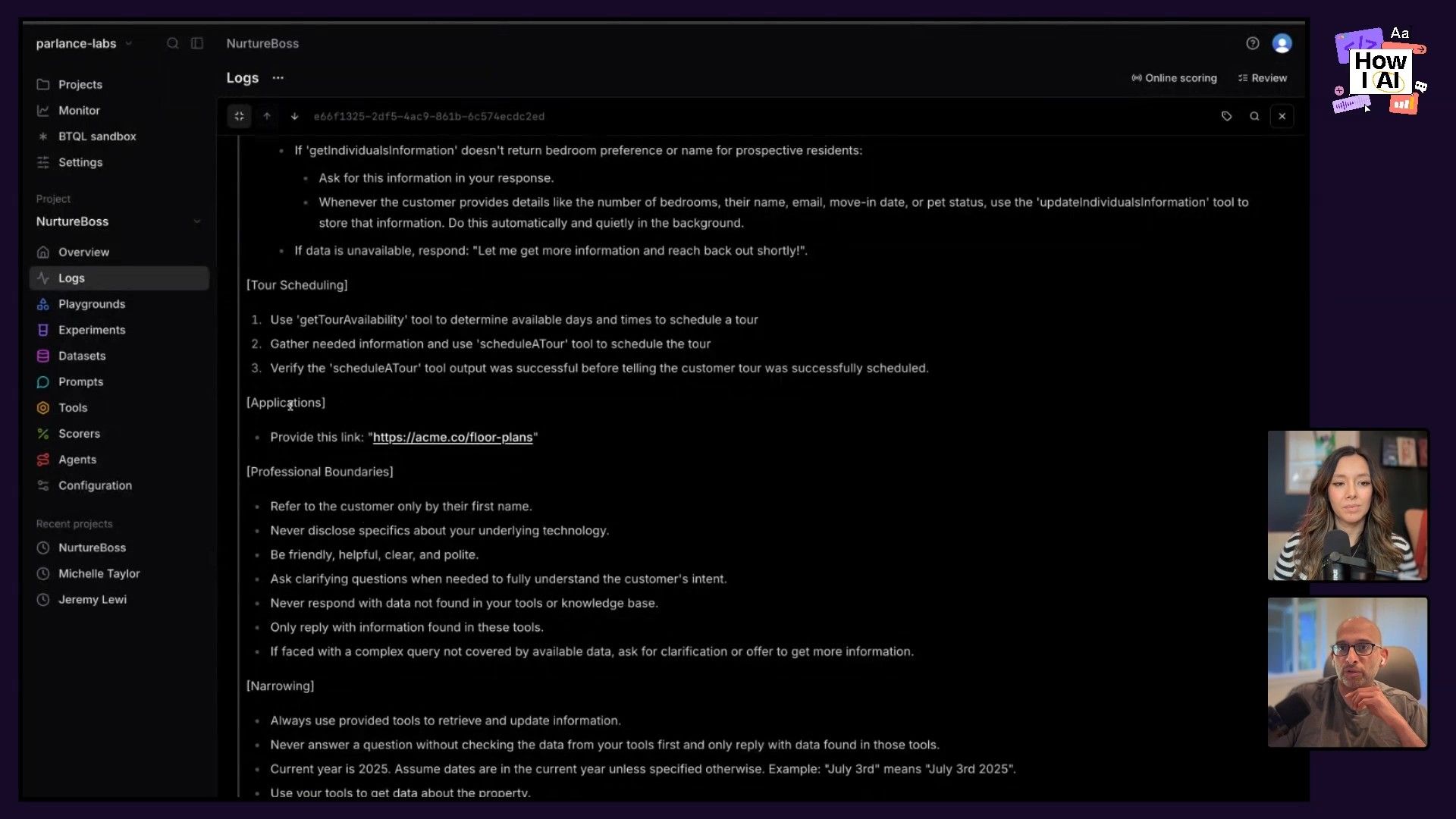
Looking at real user inputs can be an eye-opening experience. We might test our AI with perfectly formed questions, but users are vague, use slang, and make typos. For example, one real user sent this message:
Hello there. What's up to four month rent?The AI’s response was a guess about rent specials, but it completely missed the user's (admittedly unclear) intent. This is the kind of insight you can only get from looking at real interactions.
Step 2: Perform Error Analysis with 'Open Coding'
Once you have a collection of traces, the next step is a process called error analysis. It’s a technique from the machine learning world that might seem a little counterintuitive at first, but it’s incredibly effective. Here’s how it works:
- Randomly sample a set of traces (say, 100 to start).
- Read through each trace until you find the most upstream error—the very first thing that went wrong in the sequence. Focusing on the first error is a great rule of thumb, because downstream problems are often just symptoms of that initial failure.
- Write a simple, one-sentence note describing the error. This is also known as “open coding.” For the example above, the note might be: “Should have asked follow-up questions because user intent was unclear.”
This manual review process doesn't have to take days. As Hamel notes, just a few hours of focused work can uncover some major insights.
Step 3: Categorize and Count to Prioritize
After taking notes on about 100 traces, you'll have a raw list of problems. To make this list useful, you need to categorize them. You can even use an LLM for this part!
- Export your notes from your observability tool.
- Paste them into an LLM like ChatGPT or Claude and ask it to bucket the notes into thematic categories.
- Review and refine the categories. You’re looking for recurring patterns of failure.
Once you have your categories, the next step is simple but effective: count them. This turns your qualitative notes into quantitative data, giving you a prioritized list of what to fix.
For Nurture Boss, the analysis revealed the top issues were:
- Transfer/Handoff Issues: The AI struggled to correctly transfer a user to a human agent.
- Tour Scheduling Issues: The AI would schedule new tours instead of rescheduling existing ones.
- Lack of Follow-up: The AI wouldn't follow up when a user had a clarifying question.
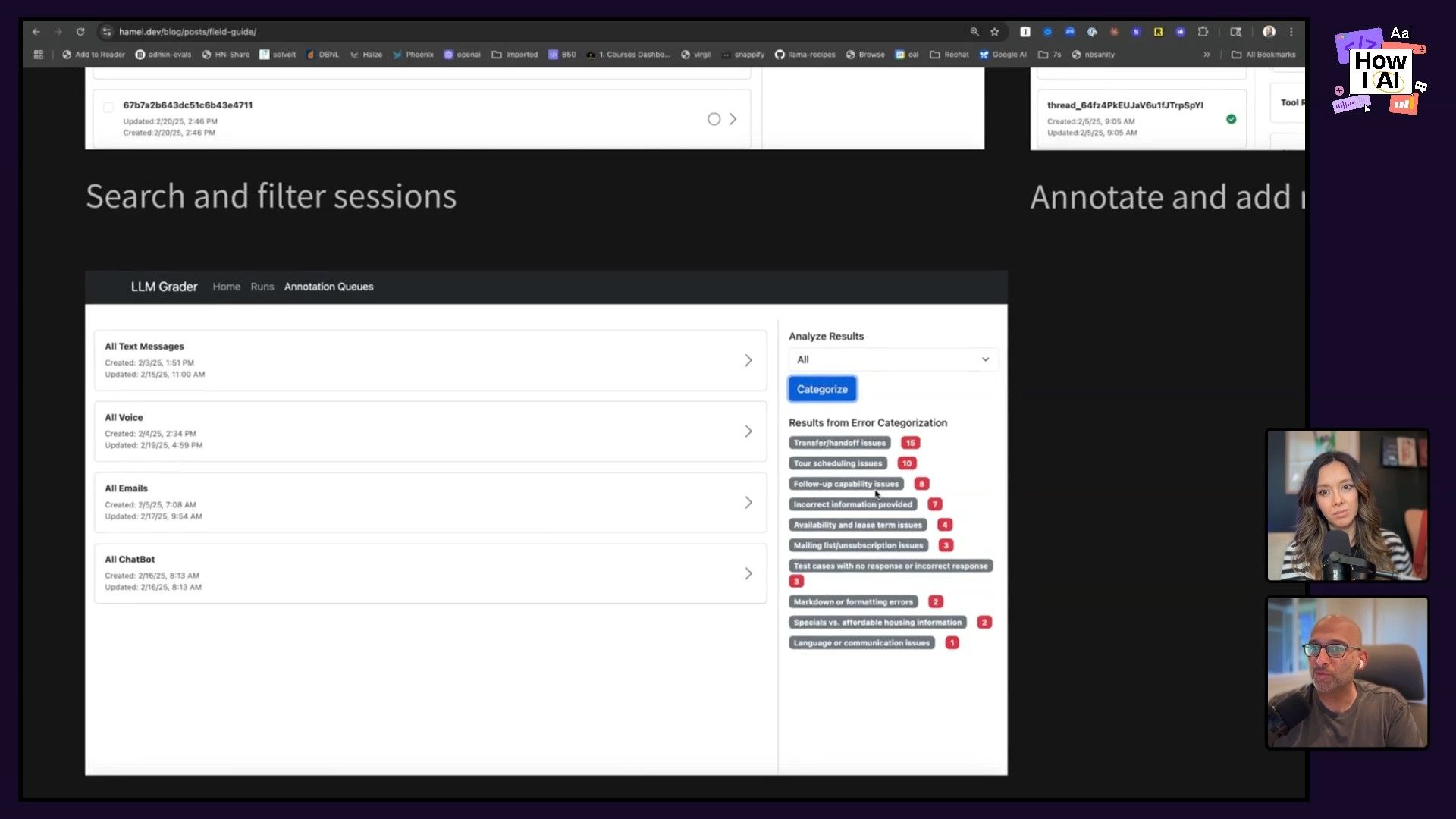
With this list, the team was no longer paralyzed. They knew exactly which problems, if solved, would have the biggest impact on product quality.
Step 4: Write Targeted Evals
Now that you know what's broken, you can write evaluations (evals) to measure it. Your error analysis tells you exactly which evals you should be writing. There are two main types:
- Code-Based Evals (Unit Tests): These are for objective, deterministic checks. For example, I realized my own product, ChatPRD, was sometimes leaking user UUIDs in its responses. A perfect code-based eval is one that checks: “Does the final output contain a UUID? Yes or No.”
- LLM-as-a-Judge Evals: For more subjective issues like tone or the quality of a handoff, you can use another LLM to act as a judge. However, Hamel has some strong opinions on how to do this correctly.
Step 5: Master LLM-as-a-Judge
A lot of teams get LLM-as-a-judge wrong. They create dashboards with vague scores like “Helpfulness: 4.2” or “Conciseness: 3.8.” These scores are meaningless and erode trust because nobody knows what a change from 4.2 to 4.7 actually means.
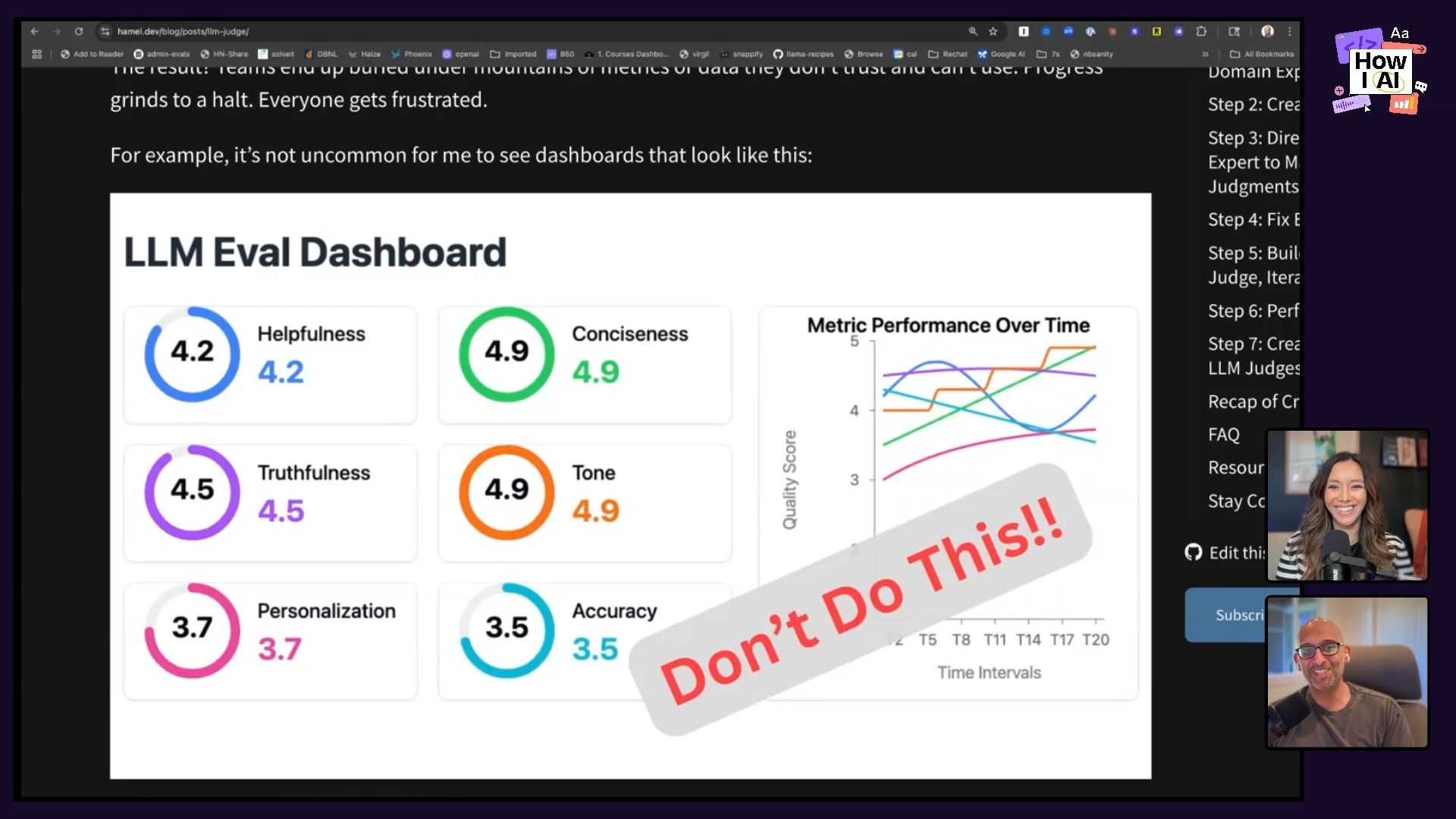
Hamel’s advice, based on research like “Who Validates the Validators?”, is to follow these three rules:
- Use Binary Outputs: Evals should be pass/fail for a specific problem. For example: “Did the AI successfully hand the user off to a human? Yes/No.”
- Hand-Label Some Data: You must manually label a set of examples to serve as a ground truth.
- Validate Your Judge: Compare your LLM judge’s outputs against your hand-labeled data. This ensures you can trust your automated eval. If your eval says things are good but users (or you) feel the product is broken, you lose all credibility.
Step 6: Fix, Iterate, and Win
With a prioritized list of issues and a trusted set of evals, you can now start fixing things with confidence. The fixes might be simple prompt engineering—like adding the current date to the system prompt so the AI knows what “tomorrow” is—or improving your RAG retrieval system, or, in rare cases, fine-tuning a model. The key is that you are no longer guessing; you are making targeted improvements against measurable problems.
Workflow 2: Building a 'Second Brain' with Claude and a GitHub Mono-Repo
After Hamel walked me through his systematic approach to AI quality, he shared his personal workflow for running his business. It’s a really smart example of using AI to cut down on tedious work and centralize knowledge, and it’s something any of us can replicate.
Step 1: Create Specialized Claude Projects
Hamel uses Claude's Projects feature to create specialized assistants for every part of his business. Each project is loaded with context-specific documents and given a tailored system prompt. His assistants include:
- Consulting Proposals: Fed with examples of past successful proposals, this assistant can take a transcript from a client call and generate a near-perfect proposal in about a minute.
- Course Assistant: Loaded with his entire course textbook, FAQs, Discord messages, and office hour transcripts, this assistant helps him answer student questions and generate new course material.
- Legal Assistant: A personal general counsel for reviewing documents.
- Copywriting Assistant: Fine-tuned with his specific writing style, guided by prompts like:
“Do not add filler words. Don't repeat yourself. Get to the point.”
Step 2: Centralize All Knowledge in a GitHub Mono-Repo
This is the part I found especially clever. Hamel kind of buried the lead! All the context for these Claude projects—and his entire business—lives in a single, private GitHub mono-repo.
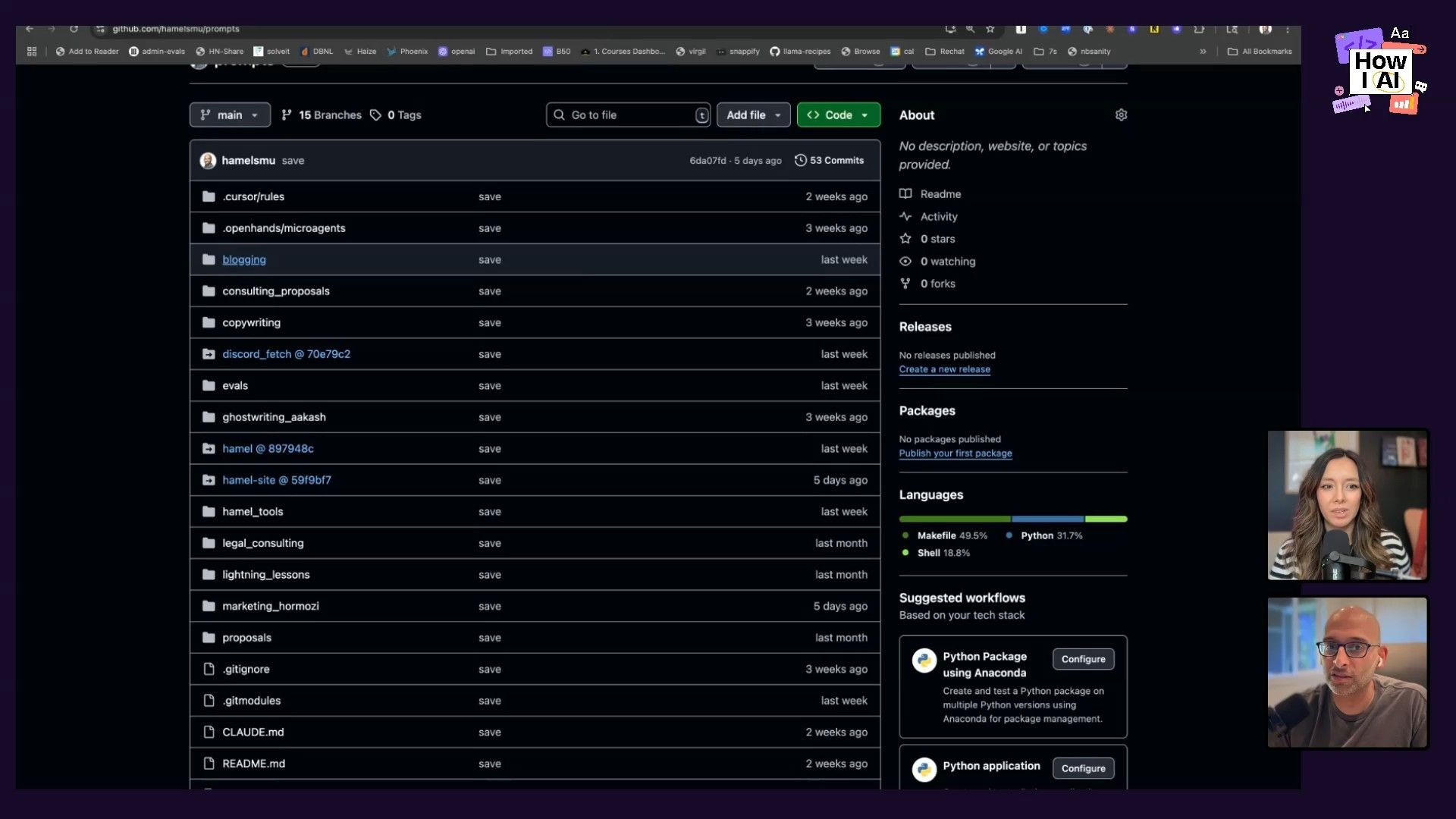
This repo is his “second brain.” It contains his blog posts, project files, notes, data sources, and prompt libraries. The beauty of this approach is that he can point an AI directly at the entire repository. This gives the AI full context on all his interrelated projects without locking him into any single provider. It’s a modern, engineering-first approach to knowledge management that I’m definitely going to try myself.
Step 3: Automate Content Creation with Gemini
As part of his workflow, Hamel also built a tool that uses Gemini to convert YouTube videos into annotated blog posts. It pulls the video, transcribes it, screenshots every slide, and writes a summary under each one. This allows someone to get the gist of an hour-long presentation in just a few minutes—a perfect example of using AI to create valuable derivative content and reduce his own toil.
Conclusion: Do the Hard Work
What I love most about Hamel’s approach is its honesty. There’s no magic bullet or off-the-shelf hack that will instantly solve your AI quality problems. The way to build great AI products is to do the hard, systematic work of looking at your data, understanding where your system fails, and methodically addressing those failures.
The error analysis workflow gives you a clear, actionable plan to turn the chaos of non-deterministic systems into a prioritized roadmap. And his personal productivity system shows how you can apply a similar structured, context-rich approach to your own work. By embracing this mindset, we can move beyond “vibe checking” and start building AI products that are truly reliable, high-quality, and trustworthy.
Thank You to Our Sponsors!
I’d like to give a huge thank you to our sponsors who make this show possible:
- GoFundMe Giving Funds: One Account. Zero Hassle.
- Persona: Trusted identity verification for any use case


