How I AI: Tim McAleer's AI Workflows for Documentary Filmmaking at Florentine Films
Discover how Tim McAleer, a producer at Ken Burns' Florentine Films, uses AI to automate post-production. This episode breaks down his workflows for building an AI-powered media database, a custom iOS app for field research, and a precision OCR tool for historical documents.
Claire Vo
For this episode, I was so excited to sit down with Tim McAleer, a producer at Ken Burns' legendary Florentine Films. Tim is in charge of the tech and processes that bring their incredible documentaries to life, and his approach to AI is one of the most practical I’ve seen.
When you think about a Ken Burns documentary, you probably picture stunning archival footage and captivating historical stories. What you might not picture is the huge effort it takes to manage all that source material. For their series on Muhammad Ali, the team gathered over 20,000 still images and hundreds of hours of footage. For years, logging, describing, and tagging all of this was a tedious, manual slog. As Tim put it, “it used to be my job, so I can tell you firsthand, not my favorite part.”
Instead of using generative AI to create new content, Tim has focused on building custom software that solves the unglamorous but essential problems of post-production. He's automated the most painful parts of research and media management, which frees up his team to do what they do best: find and tell great stories. It’s a perfect example of using AI not to replace creativity, but to speed it up.
I’m going to walk you through three of Tim's AI-powered workflows. We'll look at the custom REST API he built to automatically analyze and catalog every piece of media, a custom iOS app called 'Flip Flop' that streamlines research in physical archives, and a clever Mac utility named 'OCR Party' that makes illegible historical documents searchable. If you work with images, video, sound, or just a mountain of data, you’ll probably find some useful ideas here.
Workflow 1: Building an AI-Powered Database for Archival Assets
The biggest hurdle in documentary post-production is managing the sheer volume of assets. Every image, video clip, and audio file needs to be described, tagged, and sourced. This manual data entry was not only time-consuming but also created a bottleneck for the research team. Tim’s goal was to automate this entire process, turning a chaotic flow of media into a structured, searchable database.
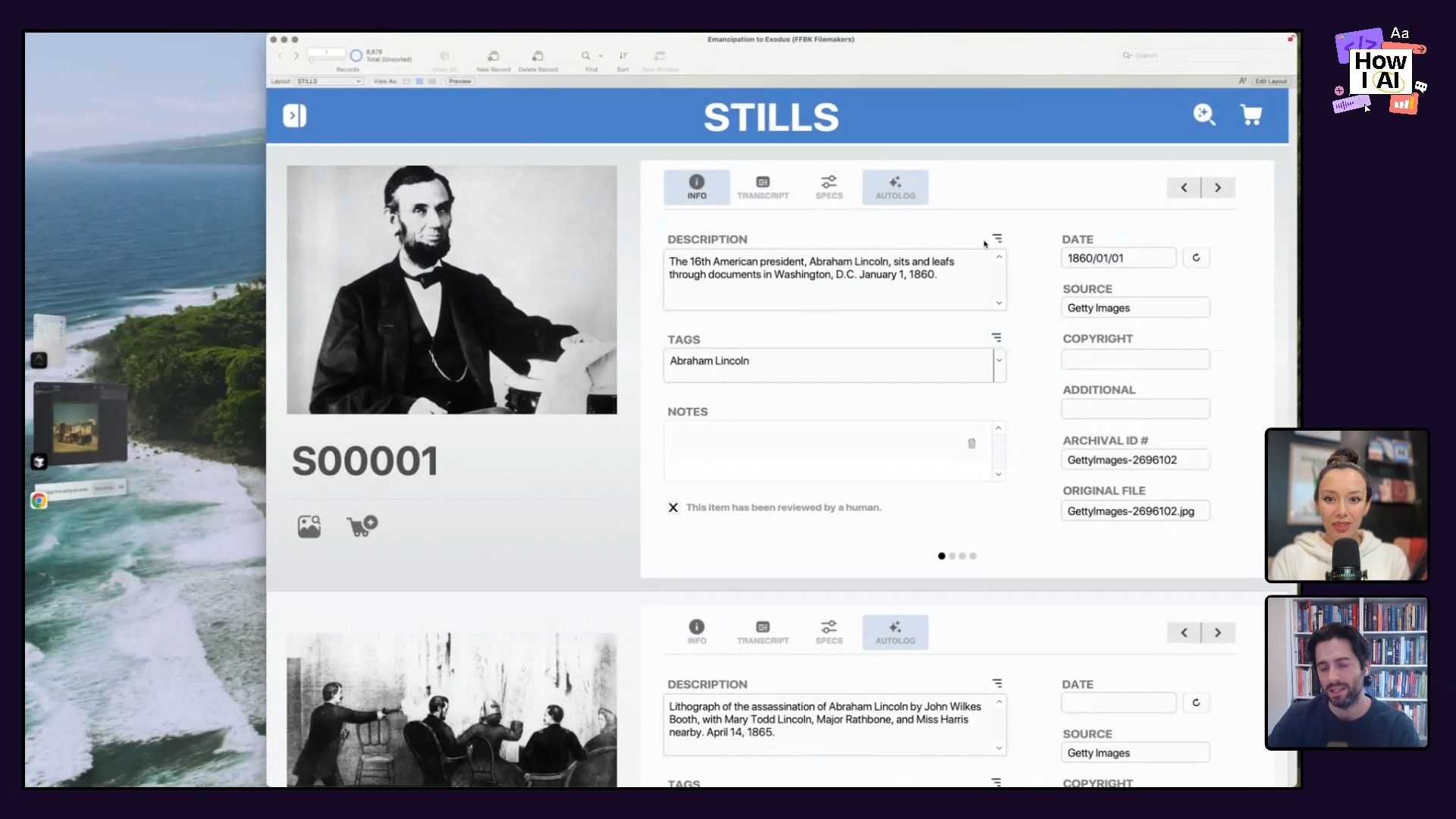
Step 1: From Manual Prompts to an Automated Script
Tim’s journey started where many of ours have: with that “aha” moment when ChatGPT added image uploads. He and his colleagues started throwing archival images at it and were impressed by the quality of the visual descriptions. The real question was how to turn this fun chat experiment into a scalable workflow.
He started by using Cursor, an AI-first code editor, to build a simple Python script. Using a voice-to-text tool called Super Whisper, he dictated his first prompt right into the editor:
“Write me a script that submits the jpeg at the root of this workspace to open ai for description. I want just a general visual description of what we can see in the image. Uh, any API credentials you need are in a text file at the root of the folder.”
The script worked, using the OpenAI Vision API to generate a decent, if generic, description: “This image depicts a small rural main street from what appears to be the mid 20th century.” This was a good start, but for a fact-checked documentary, “appears to be” isn’t good enough.
Step 2: Enhancing Accuracy with Embedded Metadata
Tim knew that archival photos, especially from sources like the Library of Congress, often contain rich embedded metadata—information like the photographer, date, and location stored right in the file. He realized the key was to make the AI use this metadata as a source of truth. He tweaked his script with a new instruction:
“I want you to add a step to this script. I wanna scrape any available metadata from the file first and append that to the prompt.”
The script now pulled the EXIF metadata, passed it to the AI along with the image, and the results were dramatically better:
“The image shows a street scene on the main street of Cascade, Idaho. Captured in 1941 by photographer Russell Lee.”
That was the breakthrough. By giving the AI factual guardrails, Tim could get detailed, accurate descriptions that were ready for the database. This process grew from just scraping embedded metadata to also scraping source URLs for even more context.
Step 3: Processing Video and Audio
With images figured out, Tim expanded the system to handle video and audio. The process for video has a few clever steps:
- Frame Sampling: The system pulls a still image every five seconds to avoid the massive cost of analyzing every single frame.
- Frame Captioning: Each sampled frame is sent to a cost-effective model (like a
GPT-4-nano) for a quick visual caption. - Audio Transcription: The audio track is transcribed in five-second chunks using Whisper, OpenAI's open-source speech-to-text model.
- Reasoning and Summarization: All the frame captions and the full audio transcript are bundled into one big prompt and sent to a more advanced model. This model weaves all the information together to generate a complete summary of what's happening in the video clip.
During our conversation, I mentioned that I’ve had great success using Google's Gemini models for video analysis, as they can automatically identify and extract interesting still frames, which might be a future enhancement for Tim's roadmap!
Step 4: Unlocking Semantic Search with Vector Embeddings
Getting accurate text descriptions was a huge step forward, but Tim pushed it further to solve the problem of discoverability. Traditional databases rely on exact keyword searches; if a researcher searched for “puppy,” they wouldn’t find an image tagged with “dog.”
To fix this, Tim implemented semantic search using vector embeddings. For every asset:
- The image thumbnail is converted into a vector embedding using an open-source model called CLIP.
- The text description is converted into a vector embedding using an OpenAI text model.
- These two embeddings are fused together, creating a rich, multi-modal representation of the asset.
This allows the team to perform reverse image searches within their own collection. An editor can find an image they like, click a “Find Similar” button, and instantly see every other asset with a similar visual style, subject, or overall vibe. This has completely changed how they find and use material from their vast archive.
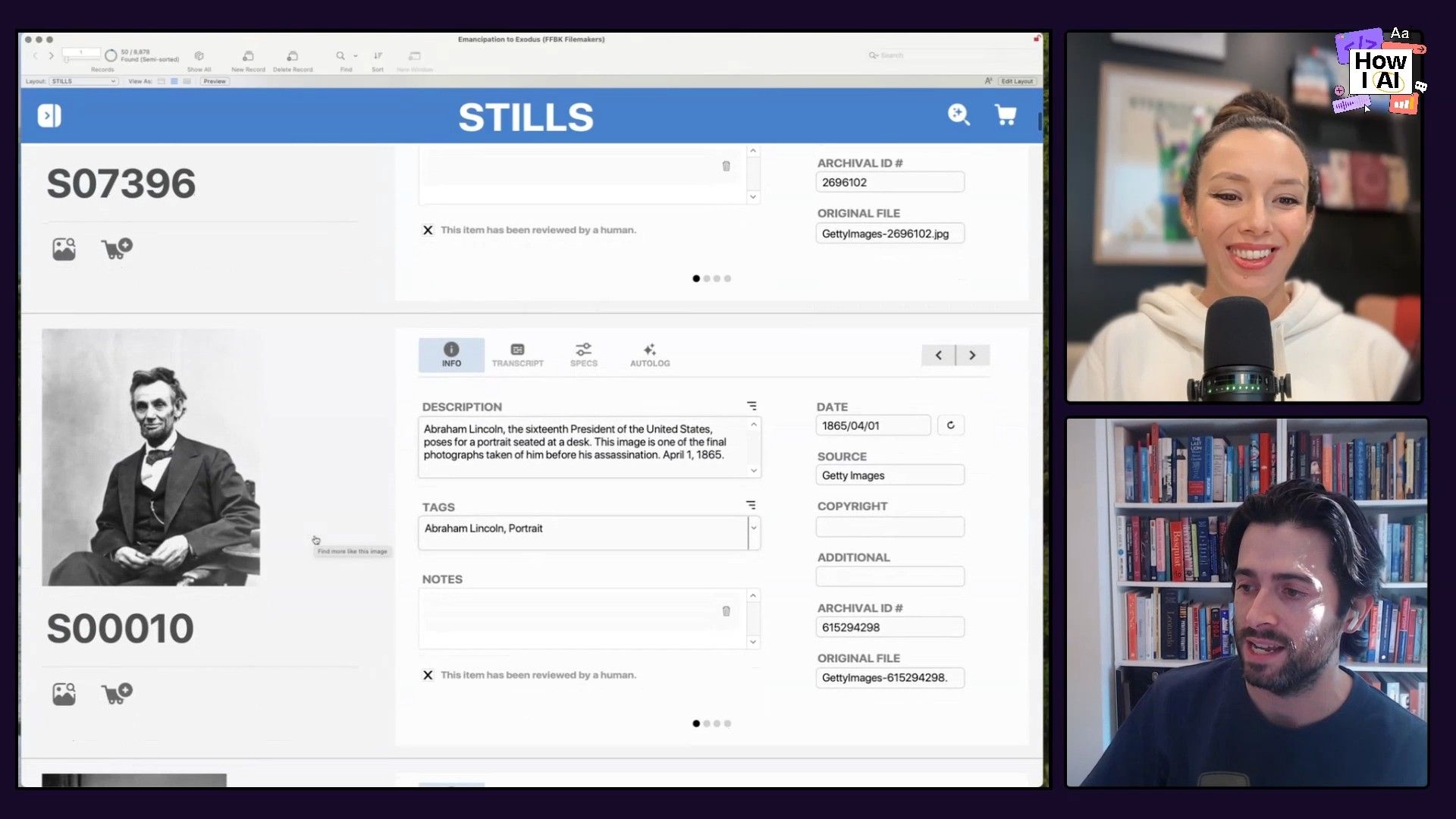
Workflow 2: 'Flip Flop' - A Custom iOS App for Streamlining Field Research
Documentary research isn’t just about digging through online databases. Tim’s team frequently visits physical archives to find hidden gems. The old process was chaotic: researchers would use their iPhones to snap thousands of photos of documents, often taking a picture of the front and then a picture of the handwritten notes on the back. Back at the office, they were left with a messy camera roll where it was nearly impossible to pair the fronts with their corresponding backs.
To solve this, Tim “vibe coded” a custom iOS app called Flip Flop. He described the screens and user flow he imagined and used ChatGPT to generate a Product Requirements Doc (PRD). He then fed that PRD to Claude, which wrote the Swift code to build the app's user interface in a single shot.
The workflow is simple but really effective:
- Create a Collection: The researcher creates a collection in the app for each folder or box of documents they are reviewing.
- Capture Front and 'Flop': They take a picture of the front of an item, then immediately tap a button to capture the “flop” side (the back).
- Automated AI Processing: As soon as the images are captured, the app sends them to the OpenAI API.
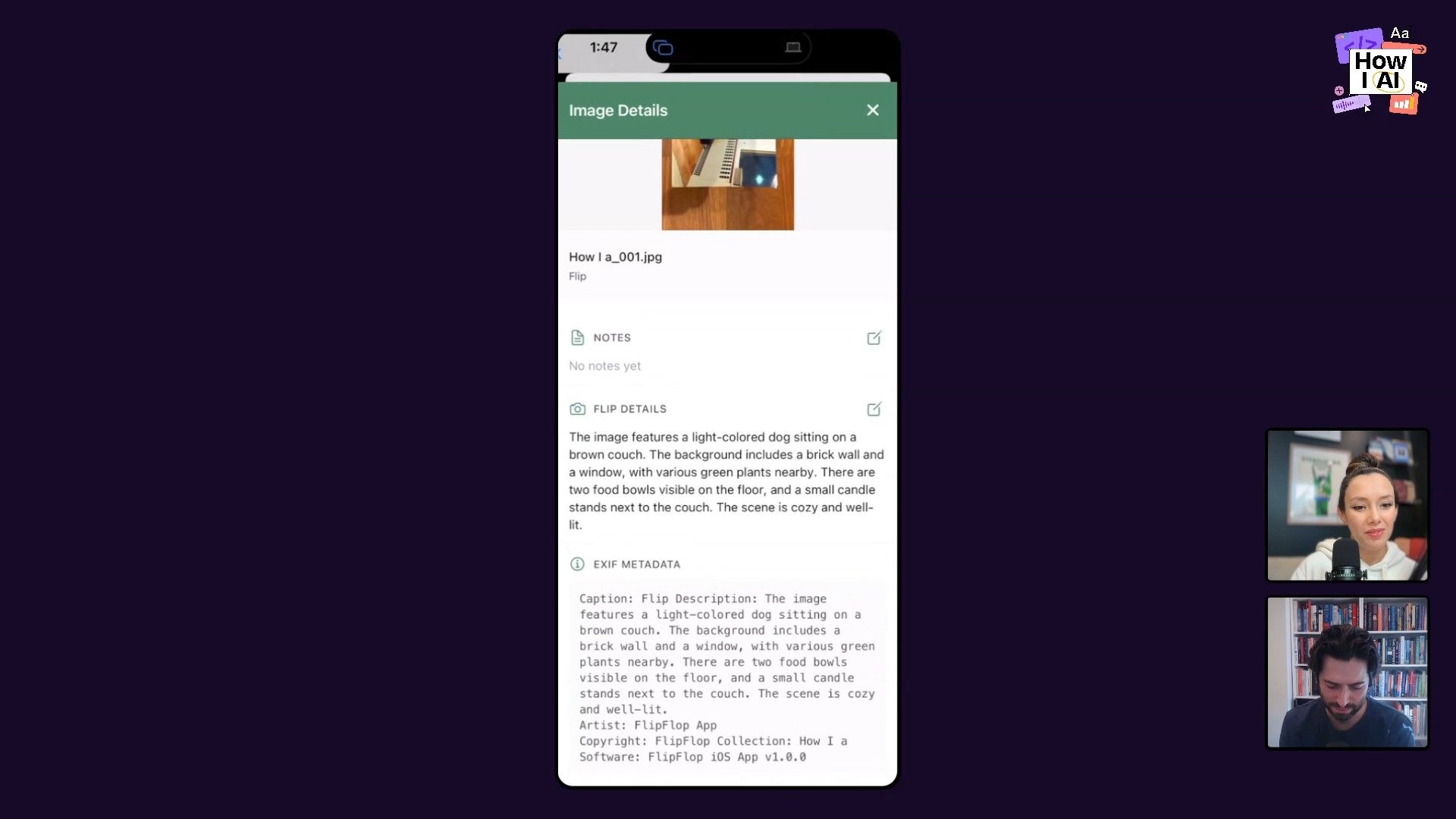
- The front image gets a visual description.
- The back image, which often has handwritten notes, is transcribed.
- Embed Metadata: And here’s the cleverest part. The app embeds all this generated information—the description, the transcription, and the collection context—directly into the image file's EXIF metadata.
This fixes multiple problems at once. The file names are structured and automatically linked, which eliminates the front/back confusion. More importantly, each image becomes a self-contained, data-rich asset. When a researcher returns with 1,400 photos, they are already organized, transcribed, and ready to be pulled into the main database. It's a great example of building a specific tool to fix a really annoying, real-world workflow problem.
Workflow 3: 'OCR Party' - A Mac App for Precision Document Analysis
The final workflow tackles another common archival challenge: getting text from complex or damaged documents. Standard OCR (Optical Character Recognition) tools struggle with old newspapers where multiple articles are crammed together, or with historical letters written in messy cursive.
Tim built another very specific tool to solve this: a Mac menu bar app called OCR Party. The name is a fun play on its function—it lets you OCR just part of an image.
Here’s how it works:
- Open and Crop: The user opens an image of a document, like an old newspaper page, in the OCR Party window.
- Select a Region: They use a simple cropping tool to draw a box around the exact section they care about—a single article, a specific paragraph, or even a single handwritten name.

- Submit for AI OCR: The cropped portion is sent to an AI model for analysis. The AI is surprisingly good at handling challenging material, including creases in the paper, ink blots, and faded text. It can even figure out words that are partially obscured.
- Get Clean Text: The app returns clean, usable text that can be copied into the database. It also notes the coordinates of the crop, so an editor can easily find the source on the original document.
This tool has been a huge help for my mom, who is a genealogist for the Daughters of the American Revolution and is constantly dealing with hard-to-read 18th-century cursive. The ability to isolate and decipher specific bits of text from dense historical documents is a huge help for any kind of research.
Conclusion: Automating Toil to Amplify Creativity
What I love most about Tim's work is how it shows the practical, immediate value of AI. He didn't set out to replace filmmakers or researchers. He set out to get rid of the tedious, repetitive work that got in their way. He built a backend API, a mobile app, and a desktop utility—three different tools, each tailored to fix a specific bottleneck in the workflow.
These tools have completely changed what his team can do. By automating data entry, they can gather more material. By making that material semantically searchable, they can find better and more relevant assets for their films. They've gone from copying and pasting text off a website to discovering thematic connections across tens of thousands of data points.
Tim’s story is a great reminder that you don't need to be a massive tech company to use AI. With tools like Cursor, Claude, and ChatGPT, anyone with a clear problem and a creative approach to “vibe coding” can build their own specific solutions. I’ll leave you with a question: what is the most painful, tedious part of your job, and could you build a small, specific AI tool to make it go away?
Episode Links
Try These Workflows
Step-by-step guides extracted from this episode.

How to Create a Custom Mac App for Precision AI-Powered OCR
Build a simple Mac menu bar utility, 'OCR Party,' that allows users to select a specific region of a document image and use AI for highly accurate text extraction, even from damaged or handwritten sources.

How to Streamline Archival Research with a Custom AI-Powered iOS App
Develop a custom iOS app like 'Flip Flop' to streamline research in physical archives. Use AI to automatically describe and transcribe photos of documents and embed the data directly into the image files.

How to Build an AI-Powered Database for Archival Media Assets
Learn to automate the cataloging of archival photos, videos, and audio. This workflow uses Python, the OpenAI Vision API, and vector embeddings to create a structured, semantically searchable media database.


