How I AI: Hamel Husain's Guide to Debugging AI Products & Writing Evals
Let's demystify debugging AI product errors and building evals with this simple guide to improving AI products.
Claire Vo
This week, I had Hamel Husain on the show, an AI consultant and educator who broke down how to debug errors in your AI product and write effective evaluations (evals). He also walked us through how he runs his entire business using some pretty impressive AI workflows.
For many of us, especially product managers, building AI products feels like uncharted territory. The technical details, the unpredictable nature of large language models, and the huge amount of data can make it incredibly difficult to ensure your product is high-quality, consistent, and reliable.
What I love about Hamel’s approach is how systematic it is. He gets you past simple “vibe checks” and into data-driven processes that lead to real, measurable improvements. He showed us that even though the technology is new, the fundamentals—like looking at your data—are the same, just with an AI twist.
Hamel shared two distinct workflows with us. The first is a methodical way to find and fix errors in AI products. The second is a peek into his personal operations, where he uses Claude and Gemini inside a GitHub monorepo to automate and streamline his entire business.
Workflow 1: Systematic Error Analysis for AI Products
One of the biggest challenges with AI products is that they fail in weird, often non-obvious ways. You might fix one prompt, but you have no idea if you’ve just broken something else or actually improved the system overall. Hamel's first workflow is a structured approach to error analysis that helps teams identify, categorize, and prioritize these AI failures so you can make progress with confidence.
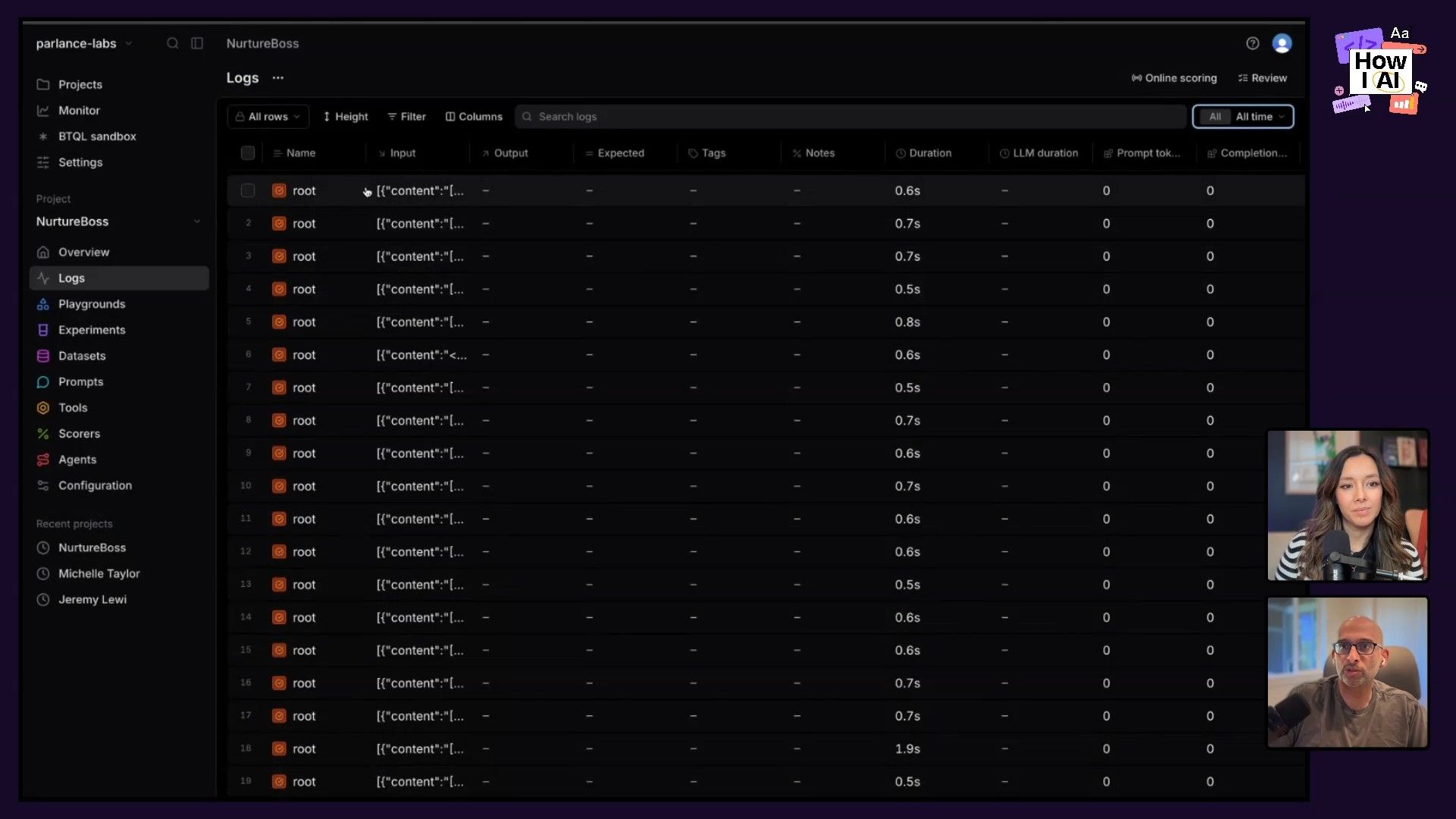
Step 1: Log and Examine Real User Traces
Hamel says the first step is simple: look at your data. For AI products, that means examining “traces,” which are the full, multi-turn conversations your AI system has with real users. These traces capture everything—user prompts, AI responses, and even internal events like tool calls, retrieval augmented generation (RAG) lookups, and system prompts. This is how you see the way people actually use your AI, typos and vague questions included, which is essential for understanding its real-world performance.
- Tools: Platforms like Braintrust or Arize are designed for logging and visualizing these AI traces. You can also build your own logging infrastructure.
- Process: Collect real user interactions from your deployed system. If you're just starting, you can generate synthetic data, but Hamel emphasizes that real user data reveals the true distribution of inputs.
- Example: Hamel demonstrated this with Nurture Boss, an AI assistant for property managers. He showed a trace where a user asked, "Hello there, what's up to four month rent?"—an ambiguous query that highlights how real users deviate from ideal test cases.


Step 2: Perform Manual Error Analysis
This part is surprisingly low-tech but effective. Instead of jumping straight to automated solutions, you just manually review a sample of traces and write down what went wrong.
This process is sometimes called “open coding” or journaling. It just means reading through conversations and making a quick one-sentence note on every error you see. The key is to stop at the very first error in the sequence of events, because that's usually the root cause of all the problems that follow.
- Process: Randomly sample about 100 traces. For each trace, read until you hit a snag—an incorrect, ambiguous, or high-friction part of the experience. Write a concise note about the error.
- Insight: Focusing on the most upstream error is a heuristic to simplify the process and get fast results. Fixing early intent clarification or tool call issues often resolves many downstream issues.
Example Note: For the "what's up to four month rent?" query, Hamel's note was: "Should have asked follow up questions about the question, what's up with four month rent? Because it's unclear user intent."
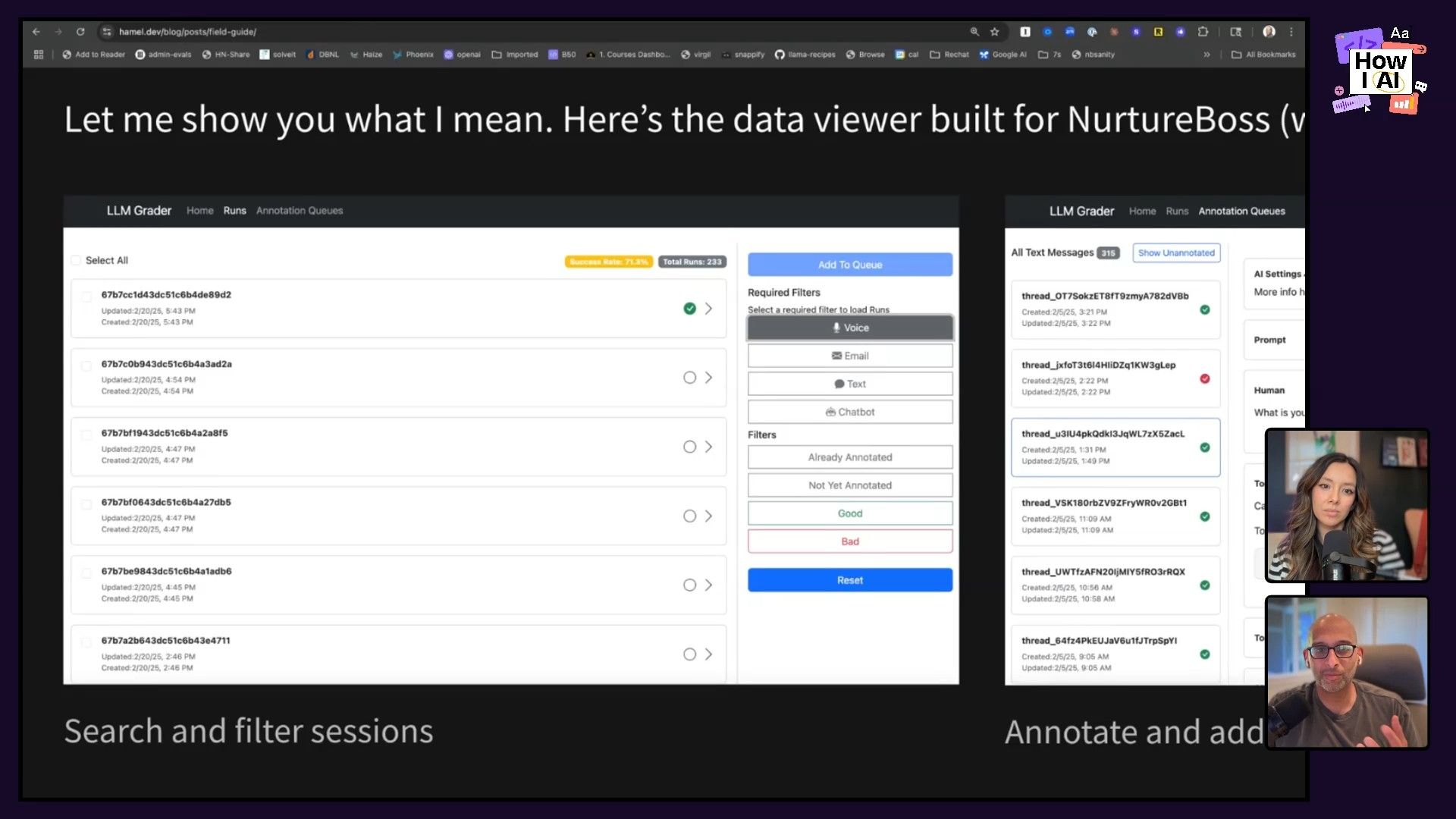
Step 3: Create a Custom Annotation System
To speed up the manual review, Hamel recommends building a custom annotation system. This doesn't have to be complicated—it could be a simple internal app or a custom view in your observability platform. The goal is to make it as easy as possible for human annotators (often product managers or subject matter experts) to quickly categorize and label issues.
- Tools: While platforms like Braintrust and Phoenix offer annotation features, a custom app can be tailored to your specific needs, channels (text message, email, chatbot), and metadata.
- Benefits: Streamlines the process, ensures human-readable output, and makes it easy to “vibe code” and quickly navigate through data.
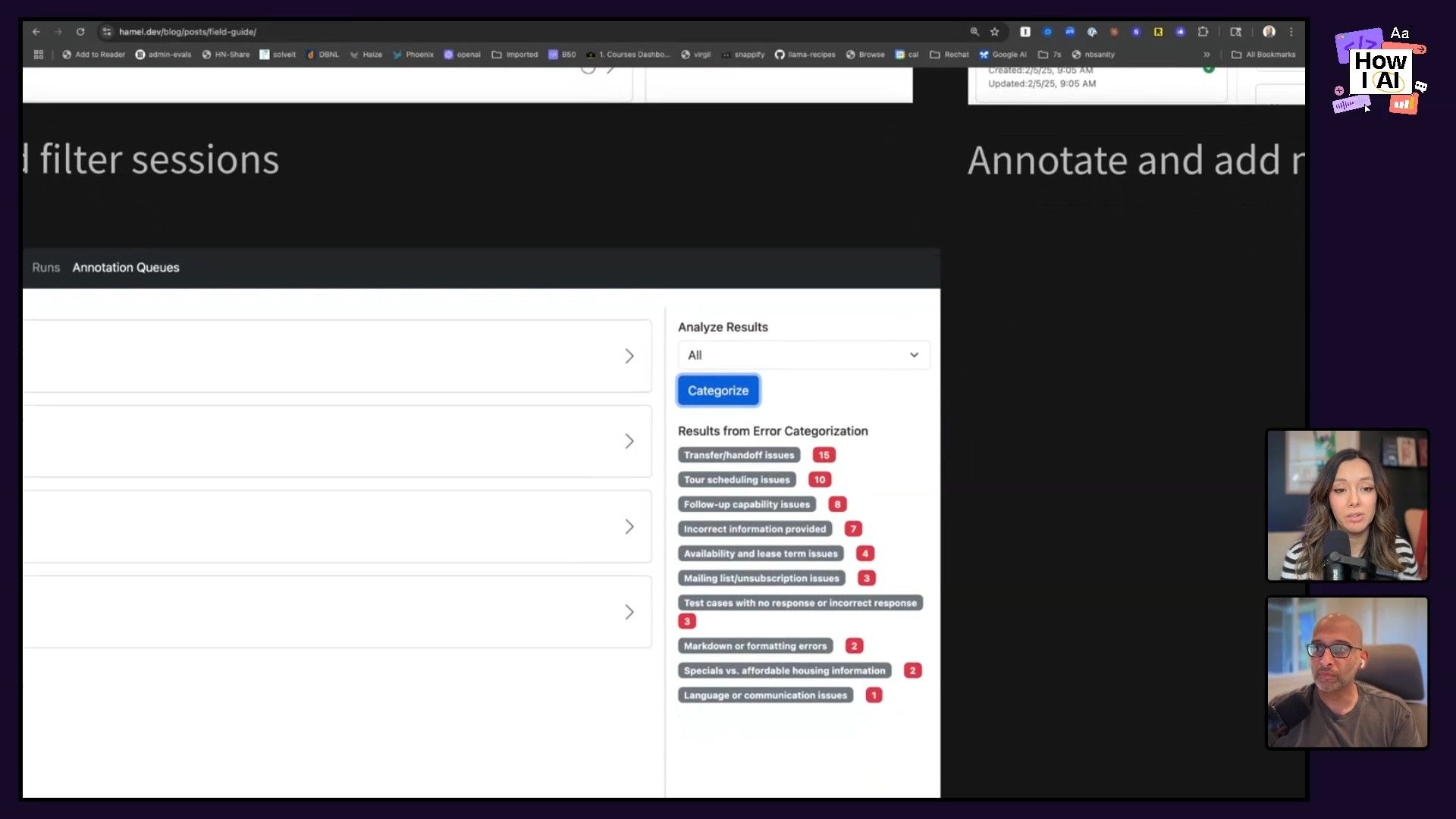
Step 4: Categorize and Prioritize Errors by Frequency Counting
Once you have a bunch of notes, it's time to categorize them. You can use an LLM like ChatGPT to help group your notes into common themes, though it might take a little back-and-forth to get the categories right. Then, you just count how many times each error category shows up. This simple frequency count gives you a clear, prioritized list of what to fix.
- Process: Aggregate all your notes. Use an LLM or manual review to group similar notes into error categories (e.g., "transfer and handoff issues," "tour scheduling issues," "incorrect information"). Count how many times each category appears.
- Outcome: This gives you a data-driven roadmap for product improvements. For Nurture Boss, this revealed common problems like AI not handing off to a human correctly or repeatedly scheduling tours instead of rescheduling them.
- Key Insight: "Counting is powerful." This simple metric gives you real confidence in what to work on next, helping you move past analysis paralysis and guesswork.
Step 5: Write Targeted Evaluations (Evals)
Now that you have prioritized error categories, you can write specific evaluations to test for these issues at scale. Evals generally come in two flavors:
- Code-based Evals: For objective, deterministic checks. If you know the exact right answer or can check for specific patterns (e.g., user IDs not appearing in responses), you can write unit tests. An excellent example is ensuring sensitive information (like UIDs from system prompts) doesn't leak into user-facing outputs.
- LLM Judges: For subjective problems that require nuanced understanding. If an error like a "transfer handoff issue" is more ambiguous, an LLM can act as a judge. However, it's critical to set these up correctly.
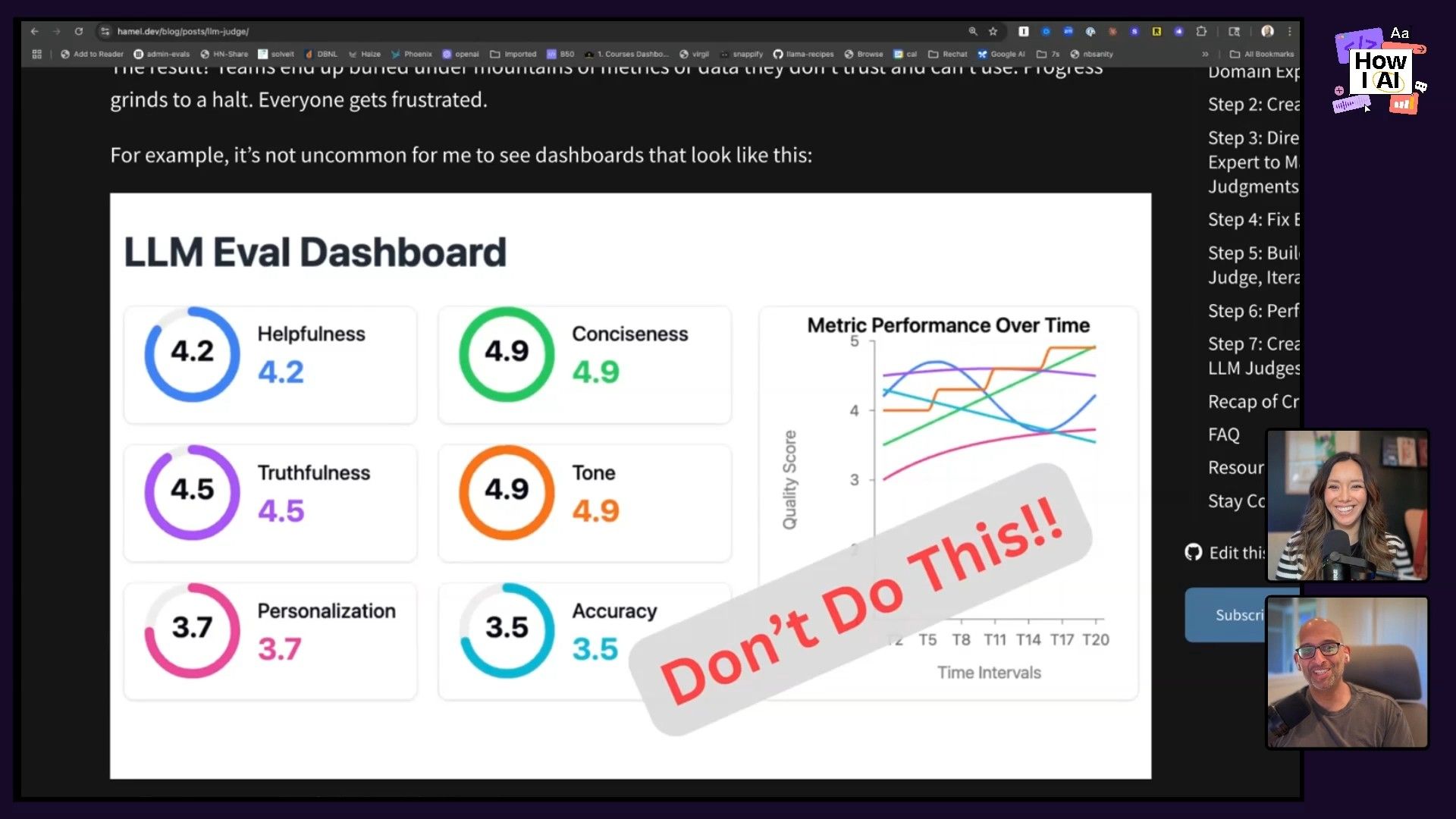
- Binary Outcomes: LLM judges should give you a simple binary result (yes/no, pass/fail) for a specific problem. They shouldn't be generating arbitrary scores (like a "helpfulness score" of 4.2 vs. 4.7, which is pretty meaningless).
- Validation: This is a big one: you must hand-label some data and compare the LLM judge's scores to the human labels. This measures the "agreement" and helps you trust your automated evals. If you skip this, you might see "good" eval scores in your dashboard while your users are having a terrible time, which is a fast way to lose their trust.
- Context: The research paper "Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences" points out that humans are often bad at writing clear instructions until they see how an LLM interprets them. The error analysis process you just did helps you figure out what you actually need, which makes your LLM judge prompts much better.
Step 6: Iterate and Improve with Prompt Engineering or Fine-Tuning
With reliable evals in place, you can keep an eye on performance and see where errors are still happening. The fixes might be simple prompt engineering (like adding today's date to a system prompt so the AI knows what "tomorrow" is), or something more involved like fine-tuning your models on the "difficult examples" you found during your error analysis. Issues with retrieval in RAG systems are a common weak spot and a good place to focus.
- Techniques: Experiment with prompt structures, add more examples to prompts, or even fine-tune models with data derived from your identified errors. As I learned with ChatPRD, even two incorrect words in a monster system prompt can significantly degrade tool calling quality.
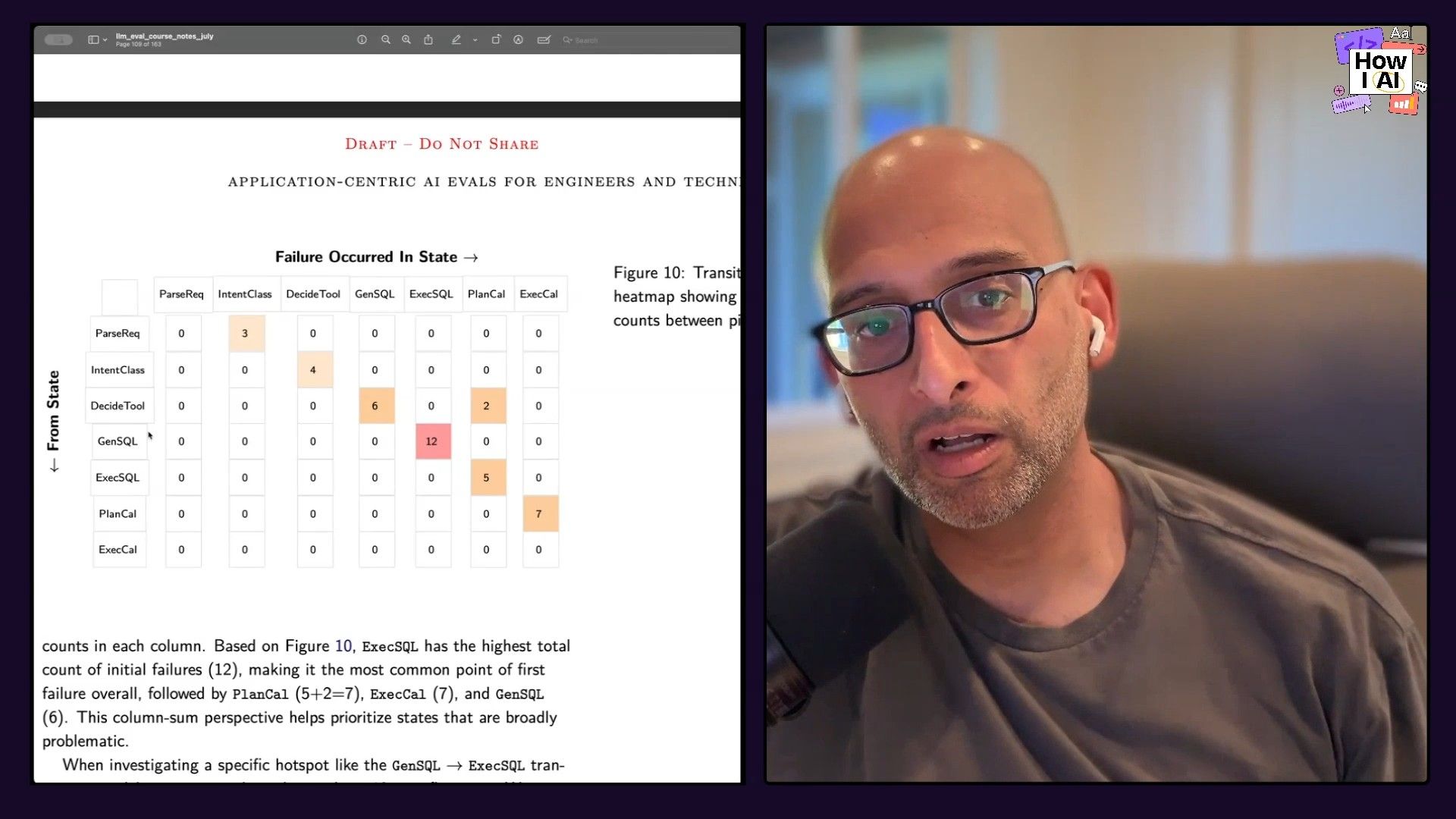
- Advanced Analytics: For agent-based systems with multiple handoffs, you can use analytical tools like transition matrices to pinpoint where errors are most likely to occur between different agent steps (e.g., generate SQL to execute SQL).
Workflow 2: Hamel Husain's AI-Powered Business Operations
Hamel doesn't just use these methods for products—he runs his entire consulting and education business with AI as a co-pilot. His setup is all about being efficient, managing context well, and not getting locked into a single AI provider, all handled from one monorepo.
Step 1: Centralized "Claude Projects" for Every Business Function
Hamel uses Claude (and a feature they used to have called "projects") to create separate, dedicated spaces for different parts of his business. Each "project" is really just a detailed set of instructions, often with examples, that tells Claude how to do a specific job.
Examples: He has projects for copywriting, a legal assistant, consulting proposals, course content generation, and creating "Lightning Lessons" (lead magnets).
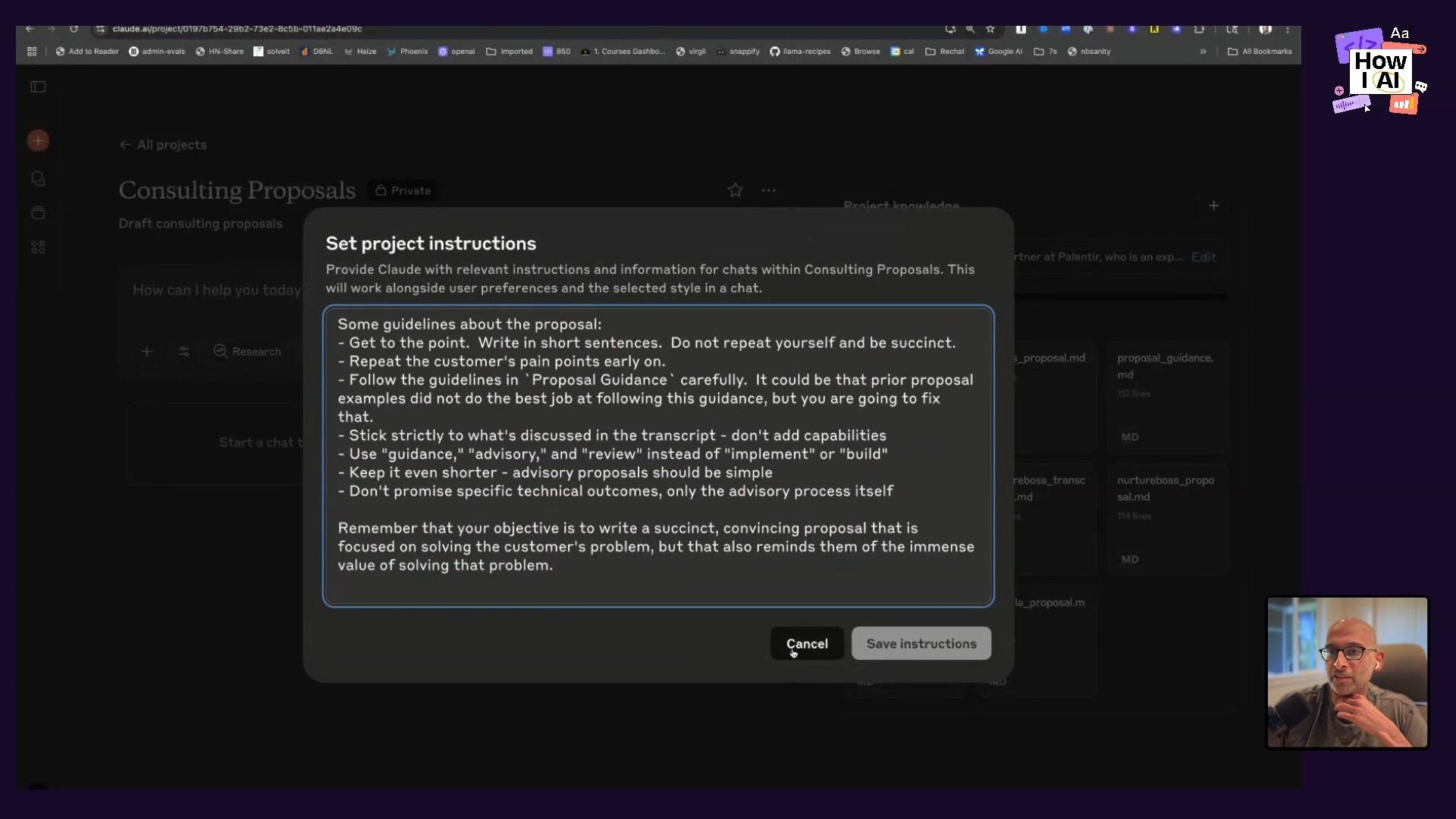
Consulting Proposals Workflow
When a client asks for a proposal, Hamel just feeds the call transcript into his "Consulting Proposals" project. The project is already loaded up with context about his skills (like "partner of Palantir's, expert generative AI"), his style guide (like "get to the point, writing short sentences"), and lots of examples. Claude then produces a proposal that's almost ready to go, requiring only a minute or so of editing.
Course Content Workflow
For his Maven course on evals, Hamel has a Claude project filled with the entire course book, a huge FAQ, transcripts, and even Discord messages. He uses this to create standalone FAQs and other course materials, all guided by a prompt that tells Claude to write concisely and without any fluff.
Step 2: Custom Software for Content Transformation with Gemini
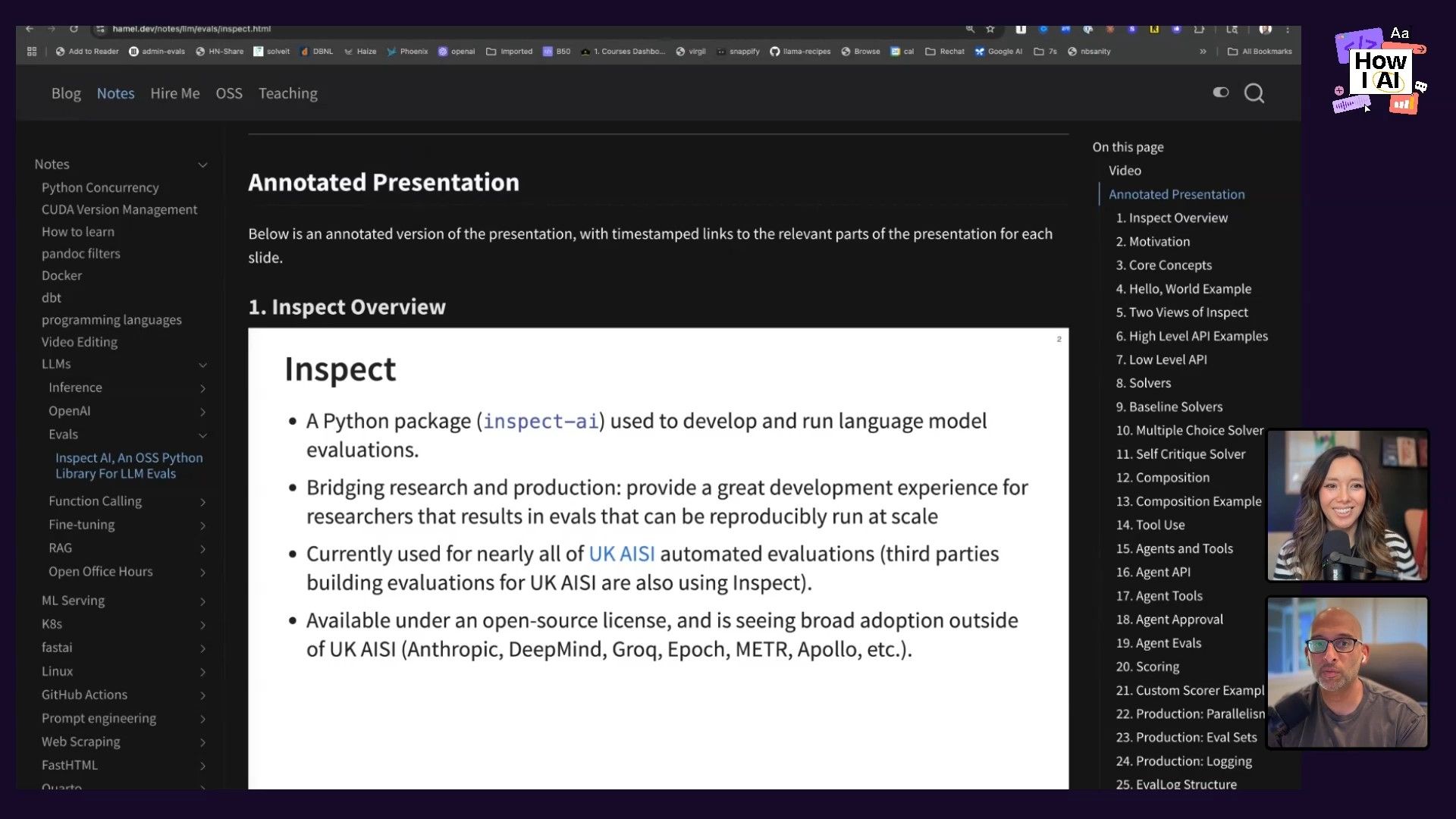
Hamel has also built his own software to automate content creation, especially for turning video content into easy-to-read formats. He does this using multimodal models like Gemini.
- Workflow: He takes a YouTube video and uses his software to create an annotated presentation. The system pulls the video transcript, and if the video has slides, it screenshots each slide and generates a summary underneath about what was said. This allows for consuming a one-hour presentation in minutes.
- Tools: Gemini models are especially good at processing video. They can pull the transcript, video, and slides all at once to create a complete, structured summary.
- Application: This is invaluable for Hamel's educational work, helping him distribute notes and make complex content digestible for his students.
Step 3: The GitHub Monorepo: The "Second Brain" for AI Workflows
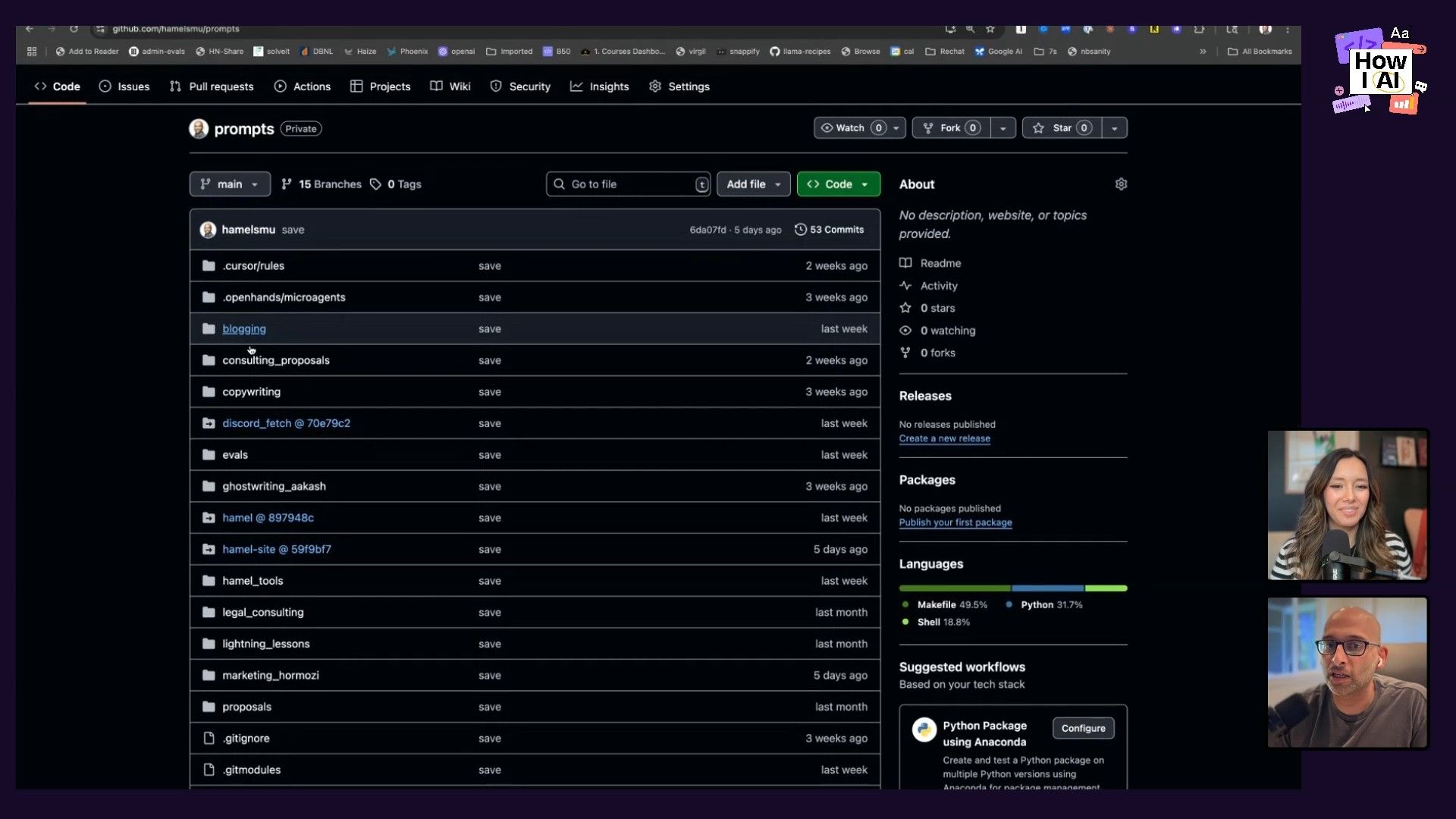
I think the most interesting part of Hamel's setup is his GitHub monorepo. This private repository is his central "second brain," holding all his data sources, notes, articles, personal writings, and his collection of prompts and tools. This way, he can give his AI co-pilots (like Claude Code or Cursor) a single, complete source of context for everything he does.
- Structure: The monorepo contains everything from his blog and the YouTube transcription project to copywriting instructions and proposals. Everything is interrelated.
- AI Access: He points his AI tools at this repo, providing a set of "Claude rules" within the repo itself. These rules instruct the AI on where to find specific information or context for different writing or development tasks (e.g., "if you need to write, look here").
- Benefits: This prevents him from getting locked into one vendor, makes sure all his context is available to the AI, and creates a highly organized, prompt-driven system for managing complex information. It's an engineer's dream for managing data and prompts in a way that really scales your personal output.
Conclusion
This was such a great episode for learning how to think about AI product development and personal productivity in a more structured way. The big takeaway for me is that improving AI quality comes down to systematic data analysis, careful error identification, and well-designed evals. Hamel’s practical advice to "do the hard work" of looking at real data, annotating errors, and validating your LLM judges is so helpful for any team building with AI.
His personal workflows also gave us a look at what a super-efficient, AI-powered business can look like. He showed us how to build a flexible system that cuts down on repetitive work and lets you scale your own expertise.
Whether you're a product manager debugging a chatbot or an entrepreneur trying to automate daily tasks, Hamel's ideas give you a clear playbook for improving your AI projects. I highly recommend checking out his website and his Maven course to learn more about his methods.
Sponsor Thanks
Brought to you by
GoFundMe Giving Funds—One Account. Zero Hassle.
Persona—Trusted identity verification for any use case
****
Episode Links
Try These Workflows
Step-by-step guides extracted from this episode.

How to Automate Business Operations with a Centralized AI 'Second Brain' in GitHub
Build a highly efficient, AI-powered personal operating system by centralizing all your business context—notes, data, and prompts—into a GitHub monorepo. This allows AI assistants like Claude or Gemini to consistently and accurately automate complex tasks like writing proposals and creating content.

How to Systematically Analyze and Debug Errors in AI Products
A structured, data-driven workflow for improving AI product quality by logging real user traces, manually analyzing errors, creating targeted evaluations (evals), and iterating on prompts or models.


